
這篇筆記整理了發表於 ICCV 2023 的 Ref-DVGO 論文。該研究探討如何在重建具有反射特徵的場景時,有效平衡重建品質與計算效率之間的關係,特別是針對現有方法在處理高反光物體時面臨的訓練時間長、資源需求高問題。論文提出了一種基於直接體素網格最佳化(Direct Voxel Grid Optimization, DVGO)的改進方法,使其具備反射感知能力。其核心思想是借鑒 Ref-NeRF 中將出射輻射(outgoing radiance)參數化為反射方向函數的概念,但將原本由大型 MLP 學習的各種屬性(如入射輻射、漫反射顏色、粗糙度、鏡面反射顏色)改由體素網格來表示和最佳化。筆記內容涵蓋了其方法細節、採用的損失函數與訓練策略(如 coarse-to-fine 和體素網格漸進縮放),並記錄了與其他方法的實驗比較結果,展示了 Ref-DVGO 在提升渲染品質的同時,顯著加快訓練和渲染速度並減少 GPU 記憶體需求。
論文資訊
- Link: https://arxiv.org/abs/2308.08530
- Conference: ICCV 2023
Introduction#
- Purpose
- 物體上單點的顏色,根據視⾓、照明、場景佈局以及該表⾯的材質屬性,可能會有很大的差異。
- 在效率和品質之間取得平衡。
- Previous Works and Challenges
- Ref-NeRF
- 通過提出將出 outgoing radiance 重新參數化為反射⽅向的函數來解決這個問題。
- 需要⼤量的訓練時間和資源,因為它的兩個⼤型 MLP 每次迭代都會被 查詢數千次。
- SDF series
- 既減少了訓練時間,⼜提⾼了渲染質量和/或更多精細的幾何形狀。
- 它們仍然需要⾄少多⼀個數量級的訓練時間和資源。
- 不⽀援(半)透明表⾯。
- Ref-NeRF
- Contribution
- 研究了⼀種基於傳統體積渲染的快速混合隱式-顯式表示, 以提⾼重建品質並加速訓練和渲染過程。
- 實驗結果證明,渲染品質有所提升,且訓練和渲染速度明顯加快,GPU 記憶體需求減少了四倍。
Methods#
Overview#
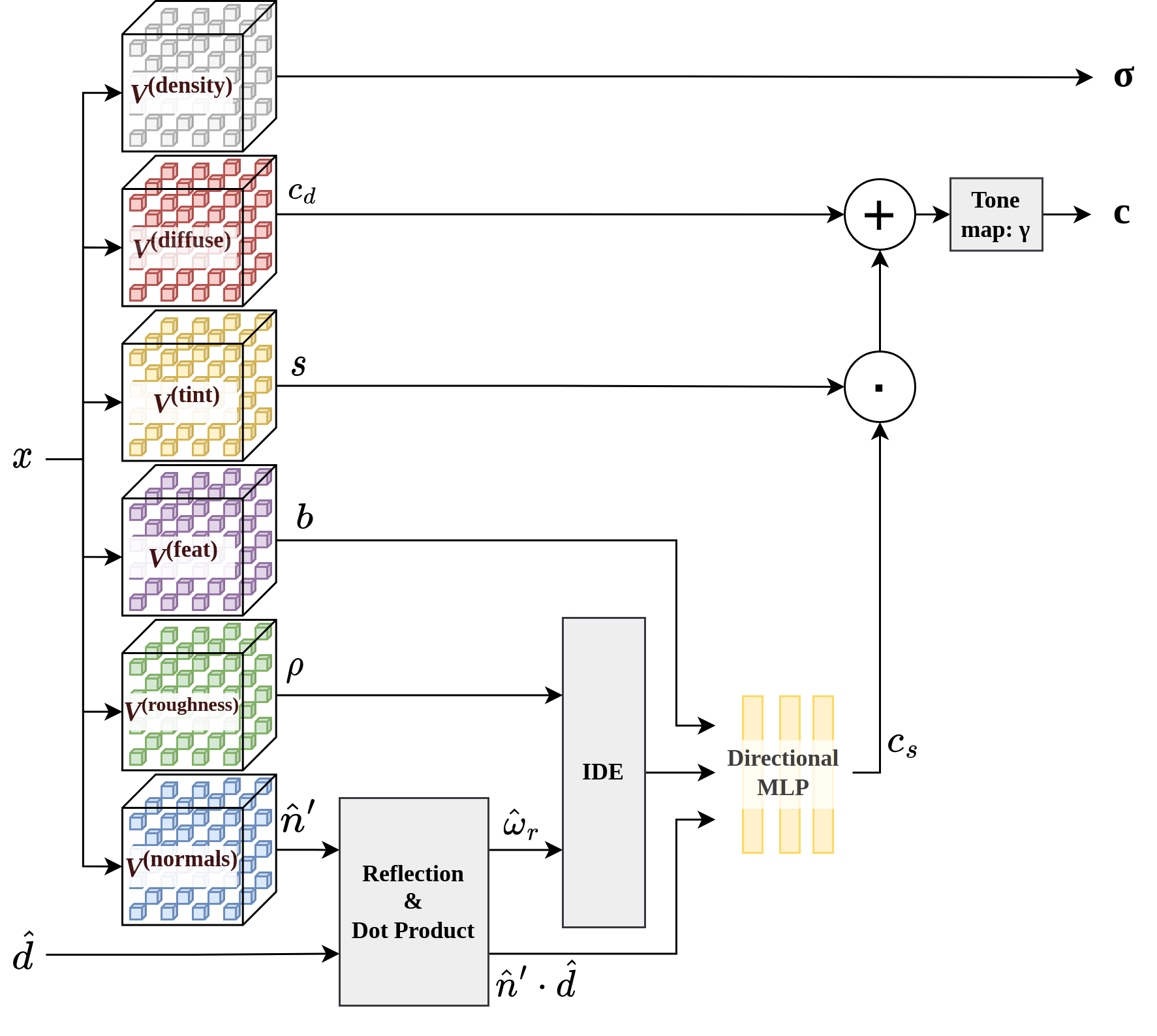
將 Ref-NeRF 中需要透過大型 MLP 生成的各種屬性,改以六個 voxel grid 表示。
Preliminaries#
本篇方法參考 Ref-NeRF 的設計
- 利⽤ outgoing radiance 的重新參數化作為反射⽅向⽽不是觀察⽅向的函數。
- 透過組合場景的 incoming radiance、diffuse color、roughness和 specular tint 屬性來表達空間中每個點的 outgoing radiance。
Optimization#
Photometric Loss $\mathcal{L}_{ph}$
Per-point RGP Loss $\mathcal{L}_{pp}$: 直接監督射線上所有採樣點的顏色。
Background Entropy Loss $\mathcal{L}_{bg}$: 正則化渲染的背景機率以減少前景和背景之間 的不確定性。
Predicted Normals Penalty $\mathcal{R}_p$: 監督預測法向量。
Normal Orientation Regularization $\mathcal{R}_o$: 懲罰背向的法向量,將所有法向量集中在物體的表⾯上,並防⽌半透明表⾯和嵌⼊或浮動偽影。
Total Variation Regularization $\mathcal{R}_{TV}$
Total final loss
$$ \mathcal{L} = w_{ph} \mathcal{L}_{ph} + w_{pp} \mathcal{L}_{pp} + w_{bg} \mathcal{L}_{bg} + w_{p} \mathcal{R}_{p} + w_{o} \mathcal{R}_{o}, $$
Training Stages#
本篇方法遵循 DVGO ,使用 coarse-to-fine 訓練策略。
- 僅對 view-independent(密度、漫反射顏⾊)的粗略模型進⾏有限次數迭代(即 5000 次)的訓練,以學習粗略幾何形狀並 refine 場景的 bounding box。
- 啟用 view-dependent components,並優化 coarse model 中的點。
此外, voxel grid 的 progressive scaling 來優化,確保模型可以先學習場景的低頻訊息,再學習高頻細節和 view-dependent 的效果。
Experiments#
Experimental Settings#
- Dataset
- Shiny Blender Dataset
- Metric
- PSNR
- SSIM
- LPIPS
- Baseline
- NeRF
- DVGO
- Instant-NGP
- Ref-NeRF
Results on Shiny Blender Dataset#
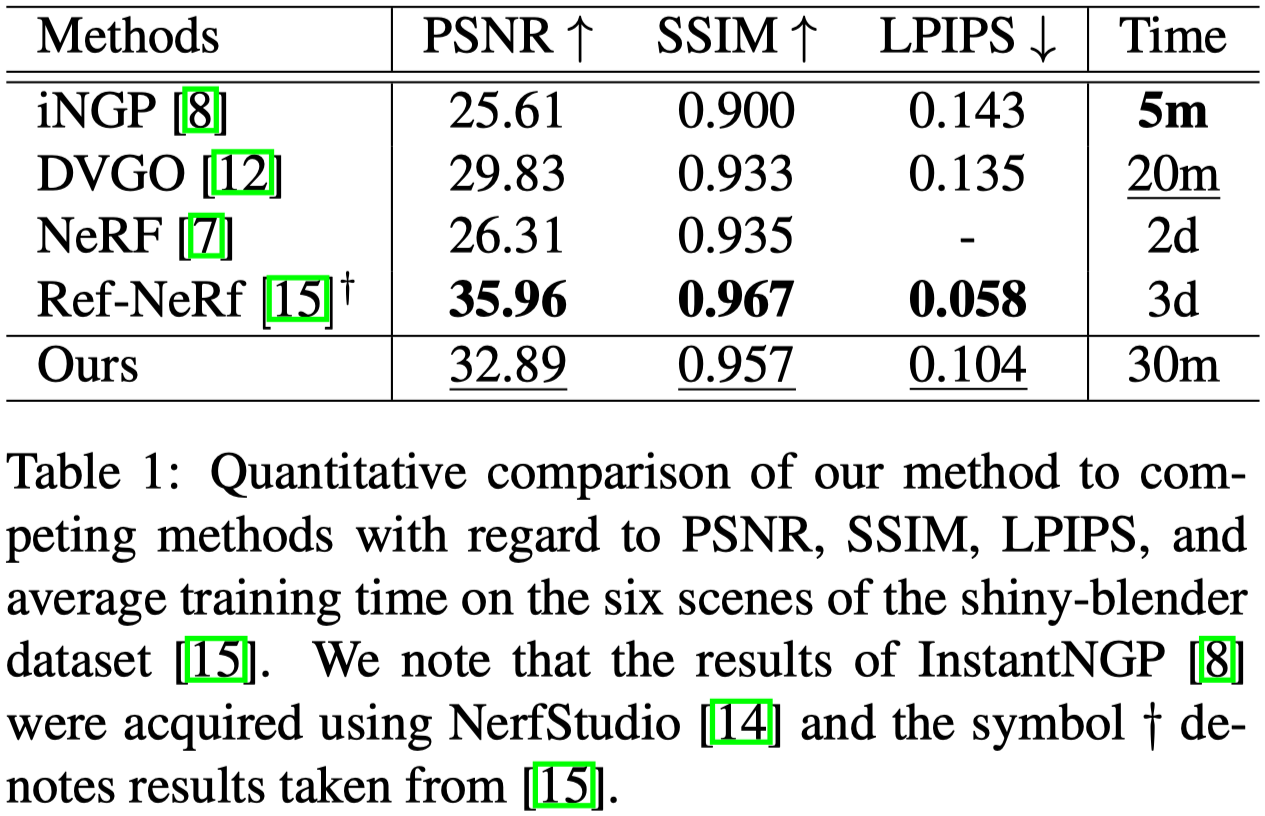
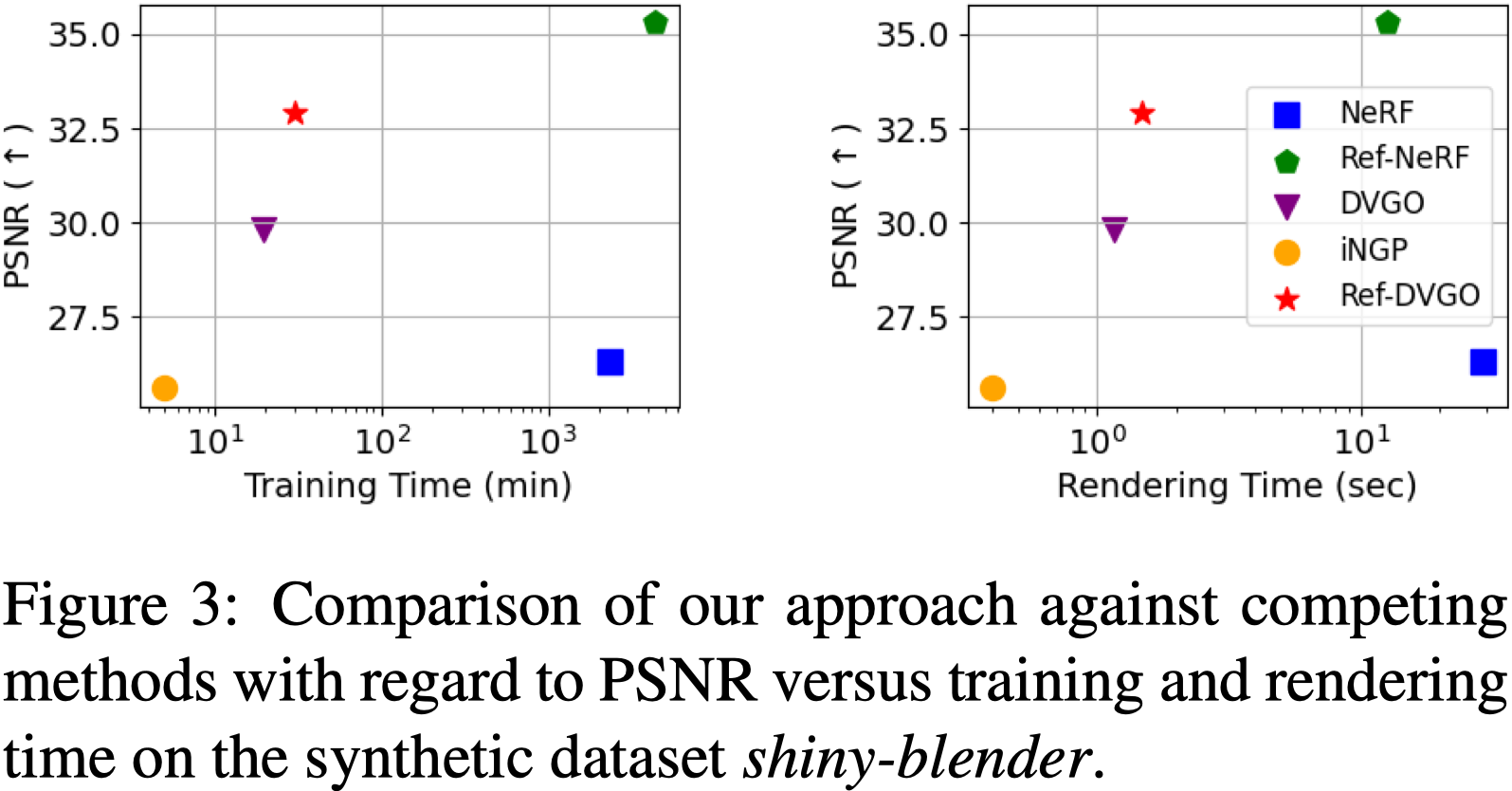
Tab.1 與 Fig.3 展⽰了重建品質和訓練/渲染時間之間的改進權衡。

Fig.2 可視化渲染圖。
Ablation Study#
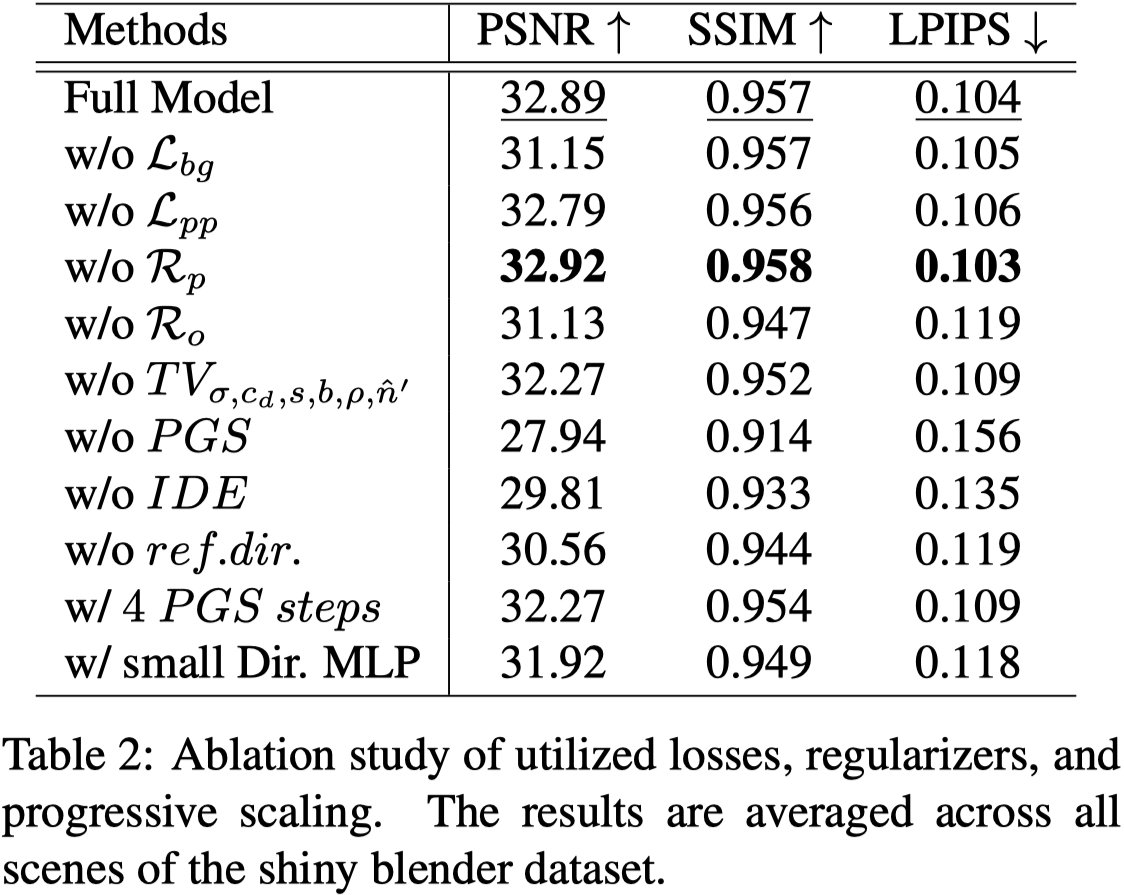
展⽰了架構和優化過程的不同組成部分的重要性。
NOTE: 移除 predicted normals penalty 會略微提⾼所有指標的表現。
Outperforming DVGO#
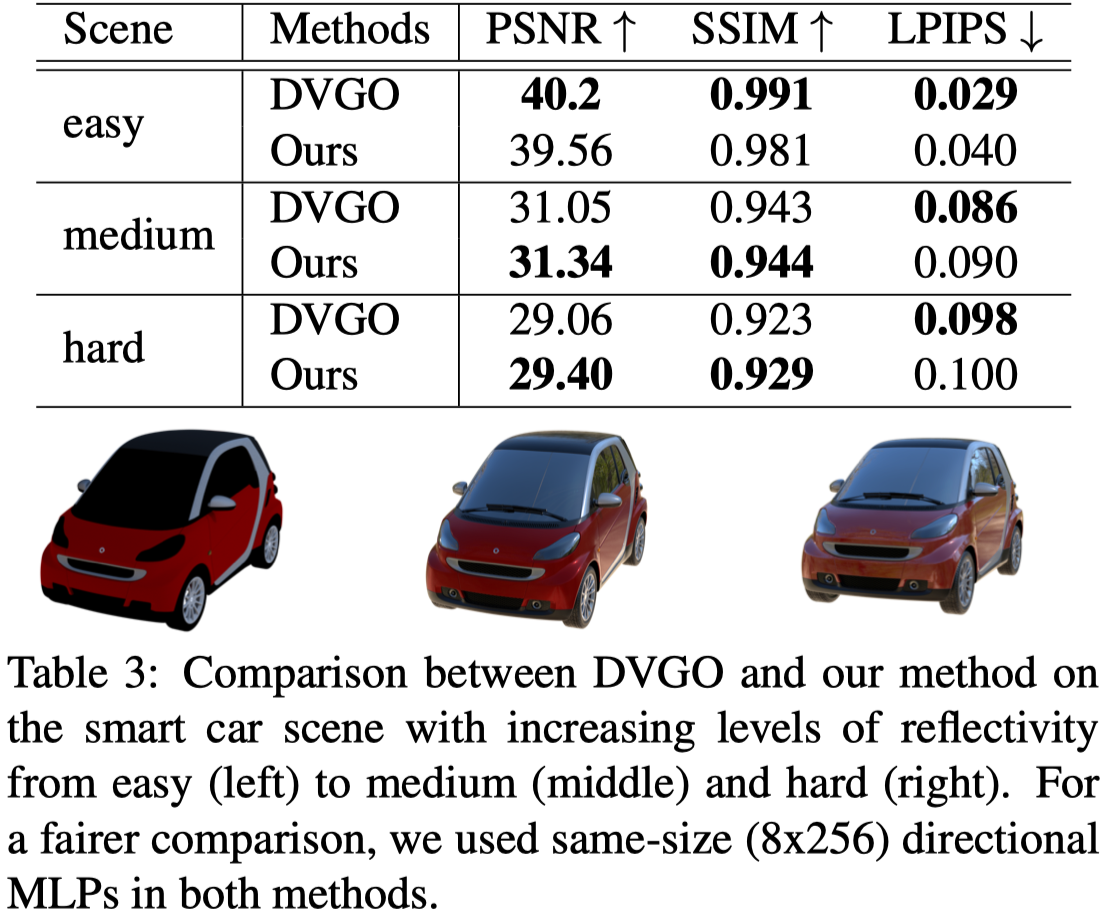
作者認為一般的模型容易受到局部極小值和過擬合的影響。
而遵循 Ref-NeRF 這樣重新參數化的方法能將模型限制在較低維度的空間,從而得到更合理的解。
如 Tab.3 所示,隨著反射和鏡⾯⾼光的複雜程度不斷增加,在高反射場景的情況下,Ref-DVGO 似乎在限制解空間方面更成功,因此優於 DVGO。
Performance Gap Against Ref-NeRF#
與 Ref-NeRF 相比,使用混合表示的方法在具有反射感知能力的情況下,可以加速。
對於效能差距,作者認為是因為使用具 voxel grid 的 spatial MLP 引入了離散化,從而打破空間連續性並減少了參數共享。
當使用 progressive scaling 與 total variation 提高空間連續性時,模型效能也相對提升。由此證明前面的假設。
Limitations#

混合表示似乎在分解 view-consistent 和 view-dependent 的外觀以支持後面步驟時遇到更大的困難,同時也導致更多的半透明表面和偽影,如擋風玻璃上的孔。
Conclusion#
- 研究了透過混合隱式-顯式表⽰來改進和加速反射場景的神經渲染的可⾏性。
- 將完全隱式反射感知神經渲染模型改編為混合隱式-顯式表⽰。
- 展⽰了改進的速度與準確度權衡。
- 討論了關於性能提⾼和未能提⾼性能背後原因的假設。