
針對可控姿勢下的人體自由視角合成,Neural Actor(SIGGRAPH Asia 2021)以 SMPL 作為幾何先驗,透過 inverse skinning 將觀測點對齊至 canonical space,並以殘差變形網路補足大位移與細微皺摺;同時將定義於 SMPL 的 2D 紋理圖作為潛在變數,配合法向圖→紋理圖的轉換網路與特徵提取器提供動態外觀先驗,緩解僅憑骨架姿勢難以描述的遮擋與模糊。該方法在長姿勢序列、挑戰性新姿勢與跨人重演中皆達到高品質自由視角渲染,並支援透過形狀參數進行人體重塑。
論文資訊
- Link: https://arxiv.org/abs/2106.02019
- Conference: SIGGRAPH Asia 2021
Introduction#
- Topic
- 從任意視⾓和任意可控姿勢下⾼品質合成⼈類。
- Problems
- NeRF 僅能從靜態場景中獲得良好的重建品質。但將它們應⽤於穿著⼀般服裝的⼈類的⾼品質⾃由視點渲染仍然很困難,更不用說在 novel pose 的情況下。
- Contribution
- 提出 Neural Actor (NA),用於實現對移動中的人類演員的動態幾何和外觀進行真實的自由視角合成。它可以播放長時間的姿勢序列,並為具有挑戰性的新用戶控制姿勢合成結果。
- 提出一個新的策略,利用 SMPL 作為指導來學習可變形的輻射場。此策略能夠將身體的動作拆分為 inverse skinning transformations 和 dynamic residual deformations 兩部分,而只有後者需要被學習。
- Neural Actor (NA) 通過將定義在 SMPL 上的 2D texture maps 作為 latent variables 加入,減少了 artifacts。
Methods#
Preliminaries#
本篇的的⽬標是建⽴⼀個具有與姿勢相關的幾何形狀和外觀的可動畫虛擬⾓⾊,因此在本⽂中不考慮背景合成。作者使用 color keying 來提取影像中的前景。
由於需要⾝體姿勢作為輸⼊,因此作者追蹤每⼀幀影像中的 body pose $\rho$。
基於 NeRF,作者定義了一個 pose-conditioned implicit representation:
$$ F_\theta : (x, d, \rho) \rightarrow (c, \sigma) \tag{1} \label{eq:1} $$符號 描述 $\theta$ The network parameters $x \in \mathbb{R}^3$ The spatial location $d \in \mathbb{S}^2$ The view direction $\rho$ The pose vector $𝒄 = (𝑟, 𝑔 ,𝑏)$ The color $\sigma \in \mathbb{R}_+$ The density
Challenges#
如何將姿勢資訊納⼊神經隱式表⽰中。
作者發現,簡單地透過將姿勢向量 $\rho$ 與 $(x, d)$ 連結來設計 $F_\theta$ 是不明智的。這樣的設計對於將大量的姿勢編碼到一個網路中以進行播放效率很低,並且很難應用到新的姿勢上。
僅從姿勢中學習移動人體的動態幾何細節和外觀是一個受限制的問題。
- 在任何時刻,移動人體的動態幾何細節和變化的外觀,如衣服的皺摺,並非完全由當時的骨架姿勢所決定。
- 由於無法避免的姿勢估計錯誤,學習動態和骨架姿勢之間的關聯變得更為困難。
以上的問題往往會導致輸出影像出現模糊的偽影。
Improvements#
- 利用一個 SMPL [Loper et al. 2015] 作為 3D 代理,以變形 implicit fields。
- 為了處理動態幾何和外觀的不確定性,NA 將 texture maps 作為 latent variables 加入。
Overview#
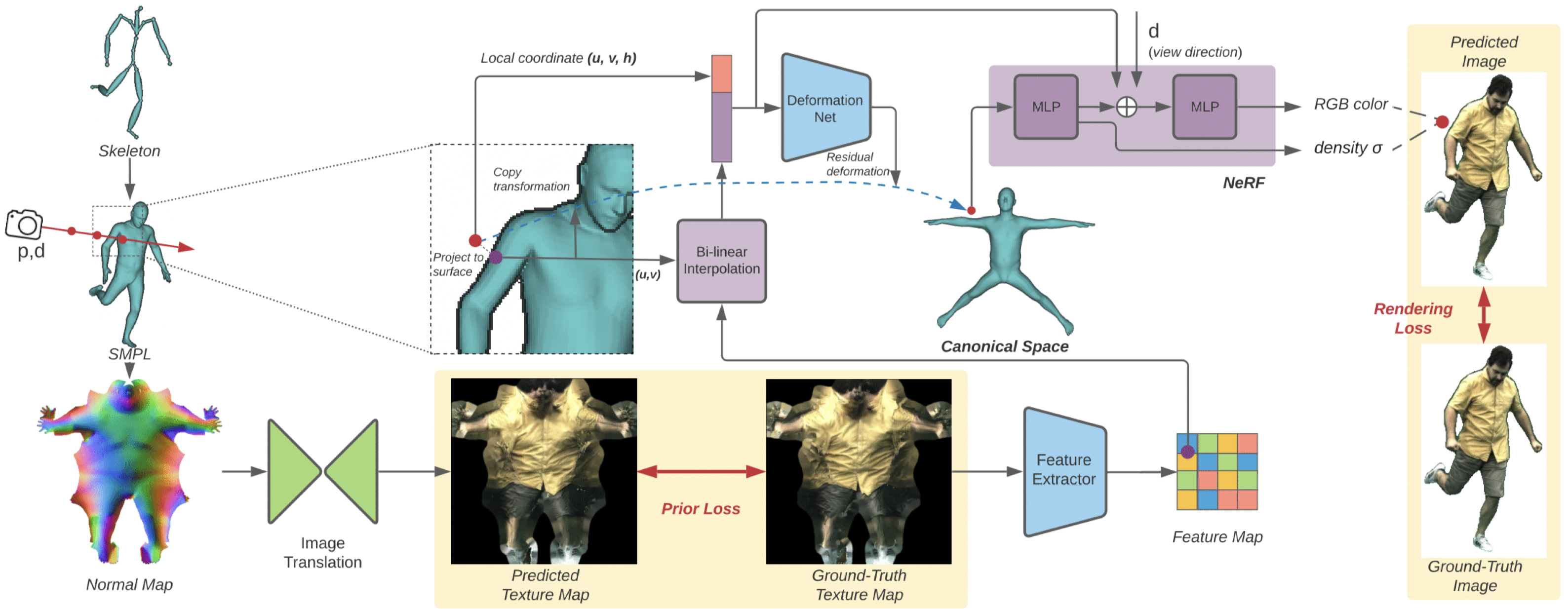
Geometry-guided Deformable NeRF#
Deformation#
先前的方法 [Park et al. 2020; Pumarola et al. 2020b; Tretschk et al. 2021] 表示通過學習一個 deformation function 來將 observed point 轉換到 shared canonical space 中是處理動態場景的有效方法。然而,受限於方法設計,這些作品很難有效地模擬相對大的運動,並且在應對新姿勢時呈現出有限的泛化能力。
為了解決這些缺陷,作者通過引用 SMPL [Loper et al. 2015] 來加強這個 deformation function。
一個以蒙皮頂點為基礎的模型 $(\mathcal{V}, \mathcal{F}, \mathcal{W})$,可在任意人體姿勢下表示多樣的身體形狀,其中 $\mathcal{V} \in \mathbb{R}^{𝑁_𝑉 \times 3}$ 為 $N_V$ 個頂點的位置,$\mathcal{F} \in \{1 \ldots 𝑁_𝑉 \}^{N_V \times 3}$ 為定義曲面三角形的頂點索引。
作者利用 inverse-skinning transformation [Huang et al. 2020] 來將 pose $\rho$ 的 SMPL mesh 轉換 canonical pose space:
$$ \Phi^{\text{SMPL}}(v, \rho, \omega) = \sum_{j=1}^{N_J} \omega_j \cdot (R^j v + t^j) \tag{2} \label{eq:2} $$| 符號 | 描述 |
|---|---|
| $(R_j, t_j)$ | 表示每個關節 $j$ 的旋轉與平移 |
Eq.\ref{eq:2} 僅定義在 SMPL 的表⾯上
對於 pose $\rho$ ,任意空間中的點,我們可以透過尋找最近的 SMLP 表面點 (Eq.\ref{eq:3}),並根據這個表面點來進行變型。
$$ (u^*, v^*, f^*) = \arg\min_{u,v,f} \|x - B_{u,v} (\mathcal{V}_{[ \mathcal{F}(f)]})\|_2^2 \tag{3} \label{eq:3} $$| 符號 | 描述 |
|---|---|
| $f \in \{1 \ldots N_F\}$ | 三角形索引 |
| $\mathcal{V}_{[ \mathcal{F}(f)]}$ | 三角形 $\mathcal{F}(f)$ 的三個頂點 |
| $(𝑢, 𝑣):\, 𝑢, 𝑣,\, 𝑢 + 𝑣 \in [0, 1]$ | 該面上的重心座標 |
| $B_{u,v}(\cdot)$ | 重心插值函數 |
接下來,我們利用 residual function $\Delta\Phi_\theta(x, \rho)$ 來建模 pose-dependent non-rigid deformation,這些變形是 standard skinning 無法捕捉的。完整的 deformation model 可以表述為 Eq.\ref{eq:4}:
$$ \Phi_\theta(x, \rho) = \Phi^{\text{SMPL}}(x, \rho, \omega^*) + \Delta\Phi_\theta(x, \rho) \tag{4} \label{eq:4} $$| 符號 | 描述 |
|---|---|
| $w^* = B_{u^*,v^*} (\mathcal{W}_{[ \mathcal{F}(f^*)]})$ | 最近表面點對應的蒙皮權重 |
有了這個設計,學習動態幾何變得更為高效,因為模型只需要為每個姿勢學習一個 residual deformation。此外,$\Delta\Phi_\theta(x, \rho)$ 用於彌補無標記動作捕捉中不可避免的跟踪錯誤。
Rendering#
當點轉換至 canonical space 後,即可通過 Eq.\ref{eq:1} 在該空間中學習 NeRF。
最終的 pixel color 可以使用 volume rendering 通過沿著射線上 $N$ 個連續樣本來預測 (Eq.\ref{eq:5}):
$$ \mathcal{I}(r, \rho) = \sum_{n=1}^{N} \left( \prod_{m=1}^{n-1} e^{-\sigma_m \cdot \delta_m} \right) \cdot \left( 1 - e^{-\sigma_n \cdot \delta_n} \right) \cdot c_n \tag{5} \label{eq:5} $$$$ \begin{align*} \sigma_n &= \sigma(\Phi_0(x_n, \rho)) \\ c_n &= c (\Phi_0(x_n, \rho), d, \rho) \\ \delta_n &= | x_n - x_{n-1} |_2 \end{align*} $$- 作者只利用 deformed point 來估算 density ($\sigma$) 以強化學習共享空間,另外同時使用 pose $\rho$ 以預測與姿勢相關的現象(例如陰影)所產生的顏色 ($c$)。
- 作者參考原始 NeRF 的方法使用兩階段訓練,第二階段會使用更多的 sampled points。他認為第一階段會先學習初始場景幾何,第二階段學習細節紋理。
Texture Map as Latent Variables#
NeRF 只能學習一個確定性的迴歸函數,這讓它不適合處理涉及動態細節模型的不確定性。從骨架姿勢到動態幾何和外觀的映射並非一個雙射關係,直接的迴歸往往會導致模糊的輸出。
作者充分利用了 SMPL template,並學習了具有 structure-aware latent variables。具體來看,他們採用了一個 2D 的 texture map $\mathcal{Z} \in \mathbb{R}^{H \times W \times C}$ 作為 latent variables,它是基於一個固定的 UV 參數化 $\mathcal{A} \in [0, 1]^{N_F \times 3 \times 2}$ 來定義的,該參數化將 3D 網格表面上的點映射到了 2D UV 平面上。
這樣做有 3 個優點:
- Texture maps 具有更高的解析度,使得它能夠捕捉到局部的細節。這些局部資訊可以被用作局部姿勢的表示,來推斷場景中的局部幾何和外觀變化。此外,相對於全局姿勢的表示(例如姿勢向量),這種局部姿勢的表示有助於提升 NA 對新姿勢的泛化能力。
- 簡單後驗 $q(\mathcal{Z} | \mathcal{I}, \rho)$ 可⽤。對於每個訓練幀,我們可以通過將每個幀的訓練影像反投影到所有可見的頂點上,並通過計算所有視角中最正交紋素的中位數來產生最終的 texture map $\mathcal{Z}$。
- 先驗模型 $p(\mathcal{Z} | \rho)$ 的學習可以被構想為一個影像到影像的轉換任務,它將從擺放的網格生成的 normal maps 映射到 texture maps。
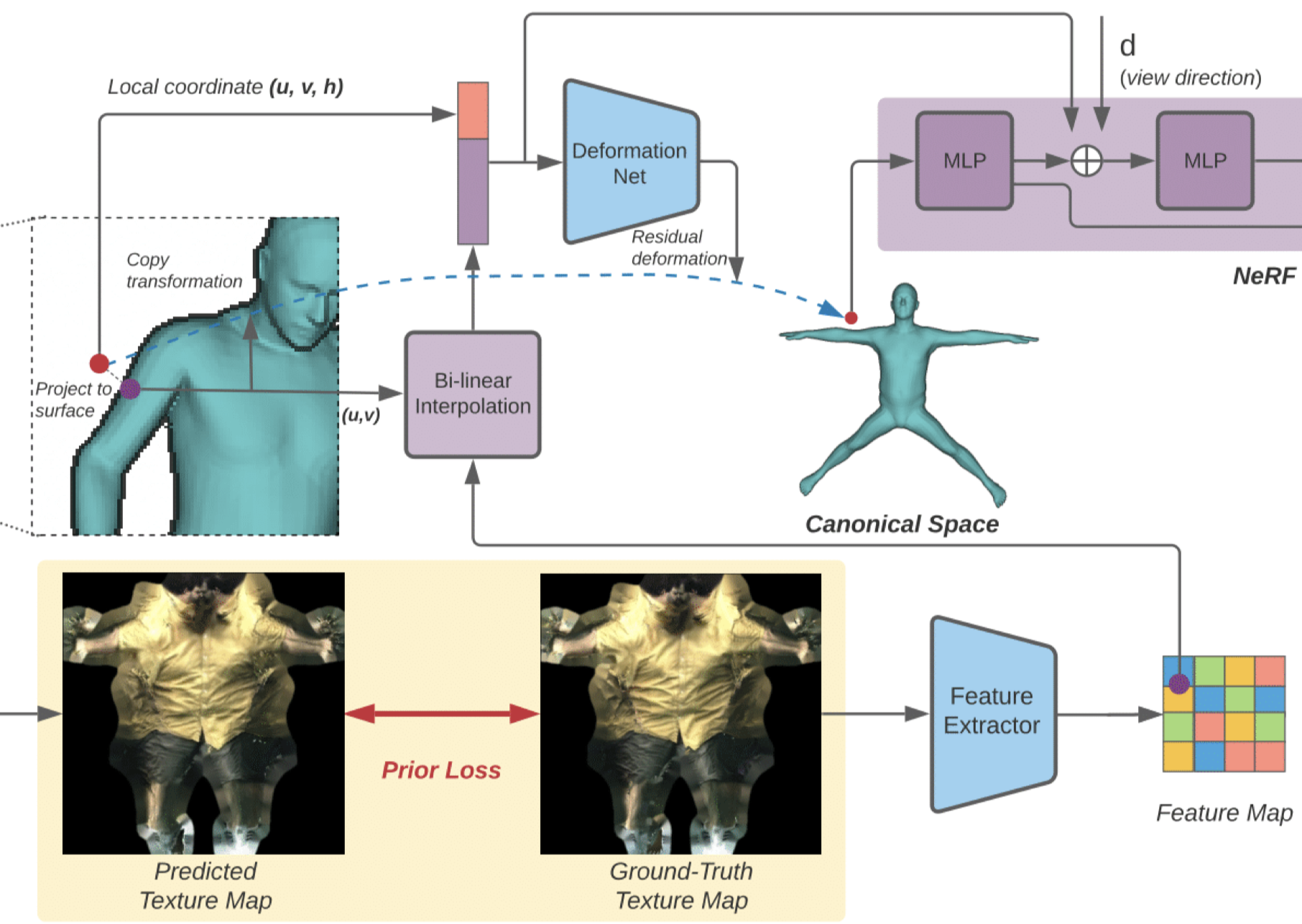
作者使用了⼀個額外的特徵提取器 $G(\cdot)$ 提取表⾯外觀的 high-level features $\mathcal{Z}$ ,其中包含比 texture map 的 RGB 值更多的資訊。
對於任何空間點 $x$,其依賴於姿勢的局部屬性依賴於通過 Eq.\ref{eq:3} 搜索到的最近表面點的 $\mathcal{Z}$ 的提取特徵,以及其局部座標 $(u,v,h)$,其中 $(u,v)$ 是最近表面點的紋理座標,而 $h$ 是到表面的 signed distance。
特徵提取器與 geometry-guided fields 一起訓練。
Experiments#
Experiment Settings#
- Datasets
- DeepCap, DynaCap
- 進⼀步評估在更廣泛的⾝體姿勢和更具挑戰性的紋理服裝:自己的 dataset
- 證明所提出⽅法的普遍性,作者也⽤來⾃不同舞蹈動作的⽅法測試:AIS, AMASS
- 這些姿勢與訓練姿勢截然不同,因此使重演任務具有挑戰性。
- Comparison Targets
- NeRF+pose
- Neural Volumes (NV) [Lombardi et al. 2019]
- Neural Body (NB) [Peng et al. 2021b]
- Multi-View Neural Human Rendering (NHR) [Wu et al. 2020]
- Data Processing
- 使⽤ color keying 來提取每個影像中的前景。
- 採⽤現成的 SMPL 追蹤系統最佳化 SMPL 的形狀參數以及全域平移和 SMPL 的位姿參數。
- 遵循 [Alldieck et al. 2018] 產⽣⽤於訓練影像 translation network 的 ground truth texture map。
- Implementation Details
- Residual deformation networks $\Delta \Phi$ 為 2 層 MLP。
- 使⽤在 ImageNet 上預訓練的 ResNet34 backbone 作為 texture feature extractor $G(\cdot)$ 從texture maps 中提取特徵。
- 訓練約需 2 天:使用 8 張 Nvidia V100 32G GPU,總計 300K 次迭代,每張 GPU 的 batch size 為 1024 條光線(rays)。
- 先驗學習:使用 vid2vid [Wang et al. 2018] 的預設設定,從 512 × 512 的法向量貼圖預測 512 × 512 的紋理貼圖;在 4 張 Nvidia Quadro RTX 8000 48G GPU 上訓練,單卡 batch size 為 4,約 10K 次迭代、歷時約 3 天。
- 測試時間:渲染一張 940 × 1285 影像約需 4 秒,並佔用 6–8G GPU 記憶體。
Qualitative Results#
Reenactment#
利用驅動人的姿勢參數和目標人的形狀參數獲得姿勢化的SMPL網格。

使用DeepCap數據集和AIST數據集的測試姿勢作為 driving poses,並在 Fig.4 中展示了重演結果的示例。
本篇的⽅法可以在各種運動中合成具有精細細節的⼈類圖像,並很好地推廣到具有挑戰性的運動。
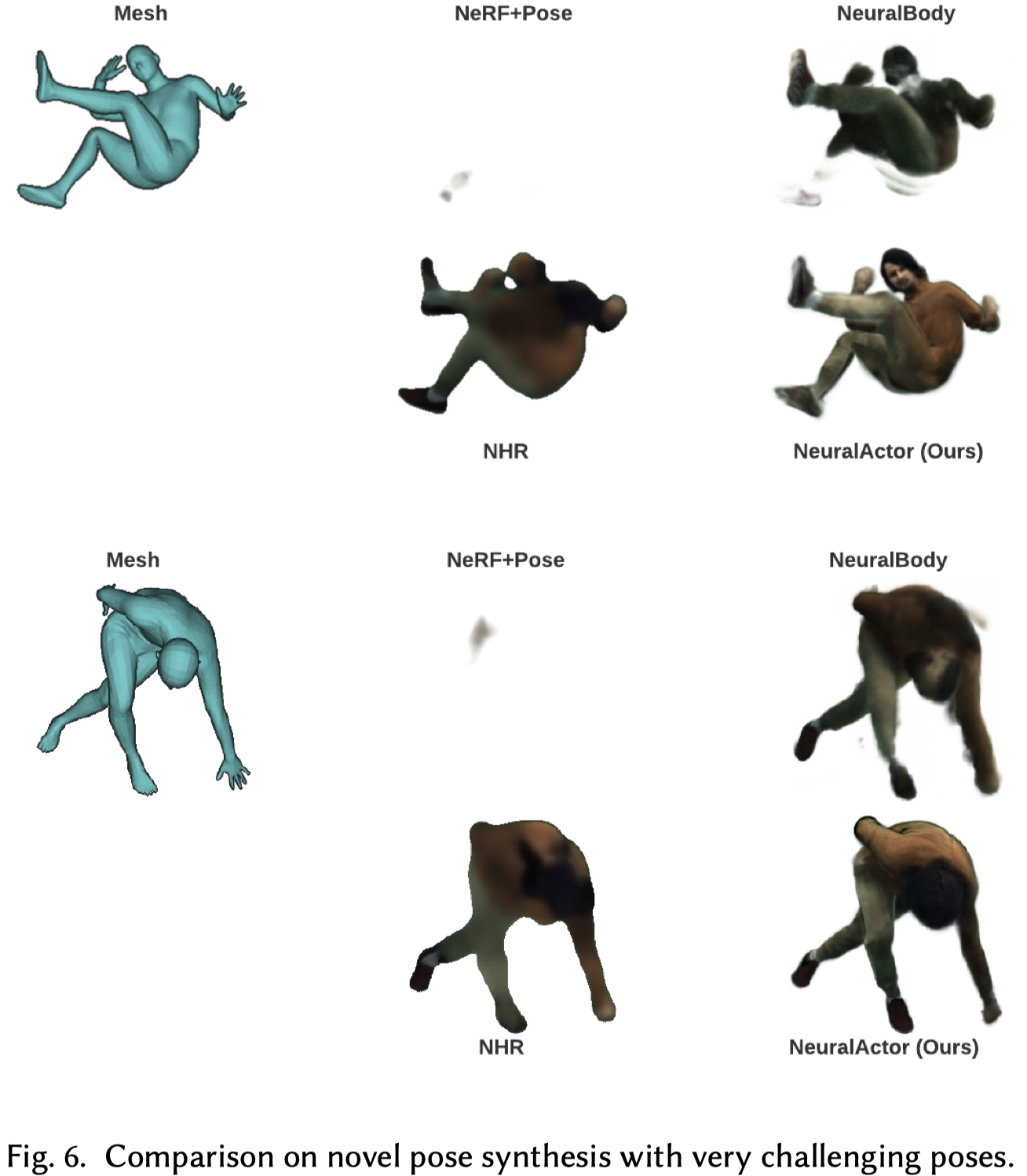
在一些非常具有挑戰性的姿勢(例如:屈腹、向前彎曲)上進一步測試 (Fig.6),我們的方法能夠產生這些困難姿勢的合理合成結果,顯著優於 baselines。
NV(可能是指的某種方法或系統)無法在一個人驅動另一個人時執行重演,因為它需要在測試時作為輸入捕獲的圖像。
Body Reshape#
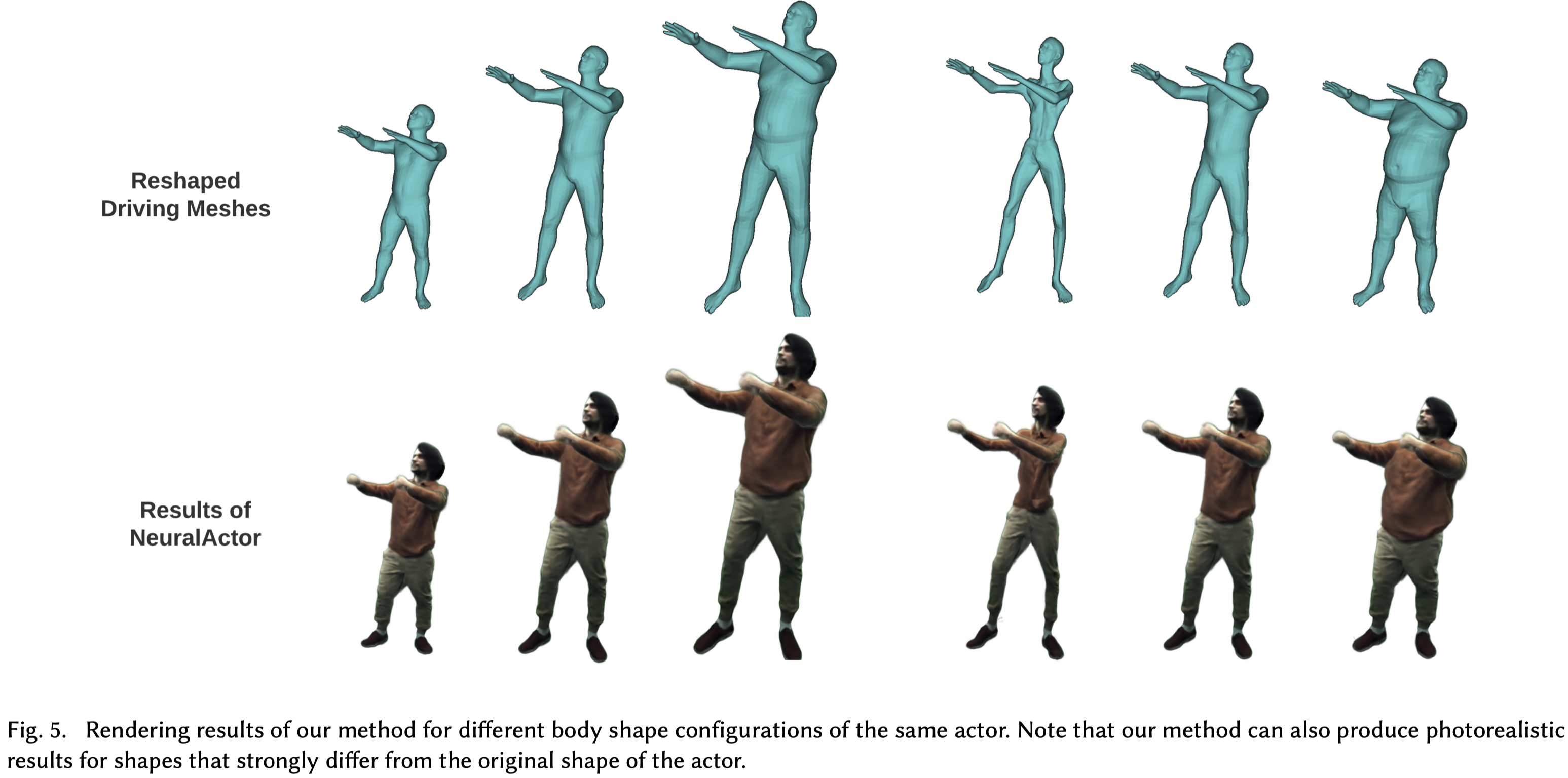
Fig.5,可以調整 SMPL template 的形狀參數 (PC1和PC2)來合成不同形狀的⼈體動畫。
Comparisons#
Novel Camera View Synthesis#
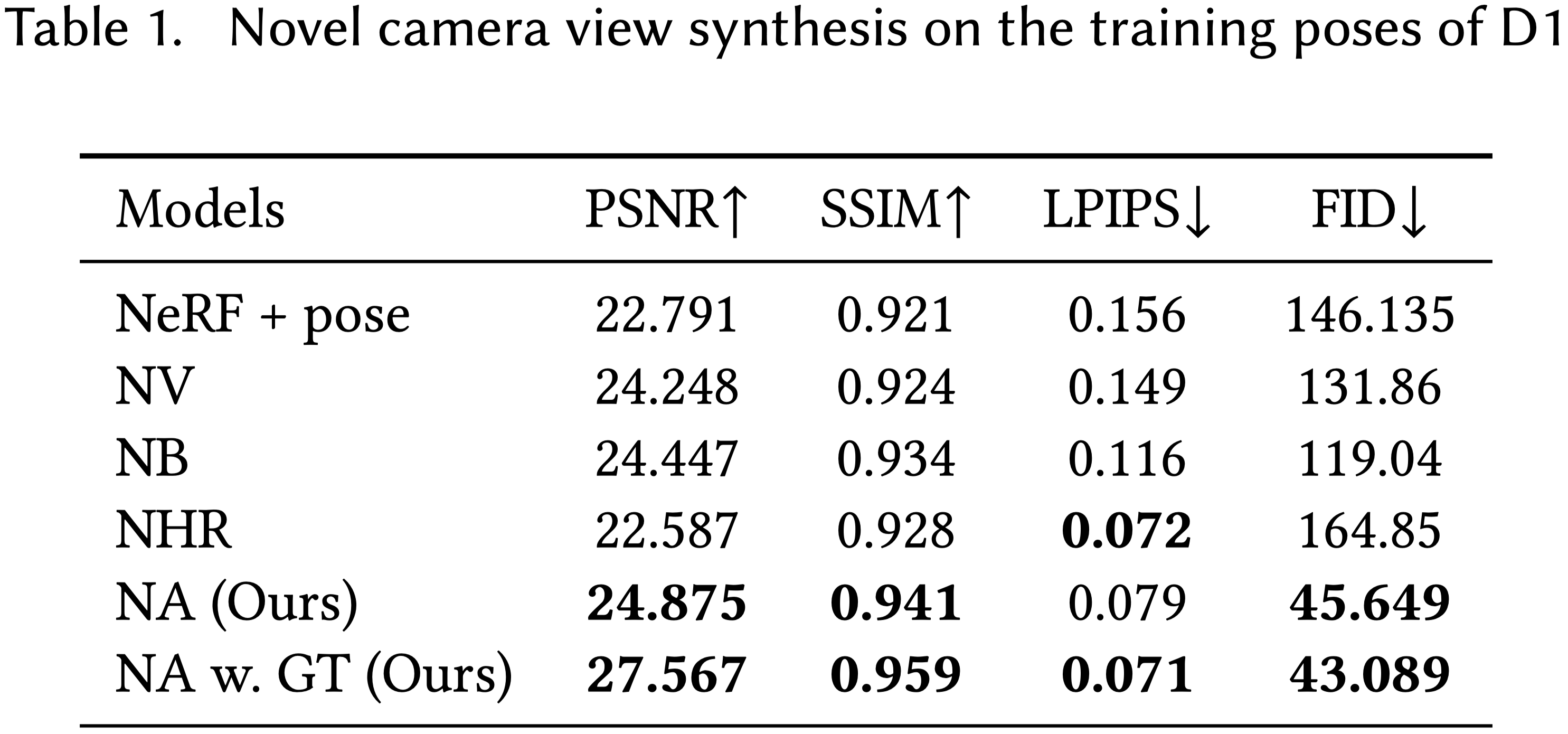
- 對於所有基線方法,當訓練集包含大量不同姿勢時,例如包含 20K 幀的姿勢序列,執行照片真實的渲染回放是困難的。
- NV 和 NB 在他們的工作中展示了良好的結果,用於播放短序列,例如 300 幀,但是,將大量幀(例如 20K 幀)編碼到單一的場景表示網絡中,會因訓練數據的大變化而導致結果模糊。
- 簡單地將姿勢向量輸入到 NeRF(NeRF+pose,類似於 [Gafni et al. 2020a] 中使用的方法)對於訓練來說並不高效,因為需要學習完整的變形。
- NeRF+pose 會因為從骨架姿勢到動態幾何和外觀的映射不確定性而產生模糊的人工物。
- NHR 也在編碼大量姿勢時遇到困難,並導致模糊的結果。
- 相比之下,通過將完整的變形分解為逆向動力學變換和殘差變形,並學習具有紋理映射的先驗以解決模糊問題,我們的方法提高了訓練效率並解決了模糊問題。
- 通過這些策略,我們可以為長序列的回放合成具有銳利動態外觀的高質量人類渲染。
Note: 當在測試時提供多視圖圖像以生成 Ground Truth texture map 時,結果可以進一步改進(見 NA w. GT)。
Novel Pose Synthesis#

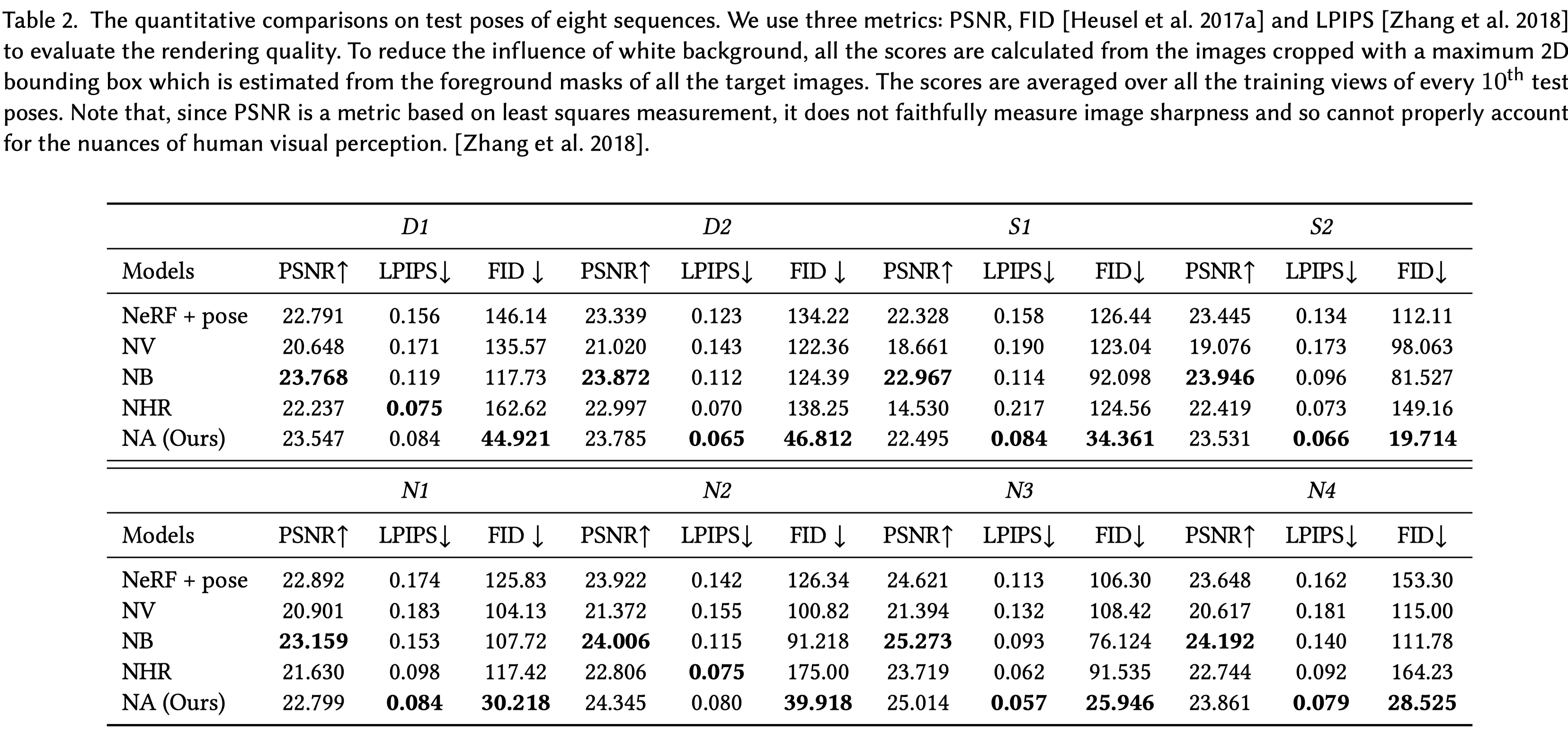
- 新姿勢合成比較:
- 與四個基線方法在八個序列上進行比較,使用測試姿勢進行評估。
- NeRF+pose 和 NV 在結果中產生嚴重的人工物,如缺失的身體部分和模糊性。
- NB 和 NHR 也受到模糊影響,無法保留結果中的動態細節。
- 我們的方法能夠很好地推廣到新的姿勢,並實現比基線方法顯著更好的、具有銳利細節的高質量結果。
- 方法設計的三個主要選擇:
- NA 將身體動作分解為逆向膚質變換和動態殘差變形,只需要學習後者,從而促進訓練效率。
- 通過將 2D texture map 作為潛在變量納入,NA 有效減輕了從骨架姿勢到動態幾何和外觀的映射不確定性。
- 高解析度 texture map 中提取的局部特徵用作推斷幾何和外觀的局部變化的局部姿勢表示,這不僅使得能夠更好地捕獲幾何細節,而 且使模型能夠很好地推廣到新的姿勢。
- 與最近的基於網格的方法 Real-time Deep Dynamic Characters (DDC)的比較:
在 D1 序列上進行比較,原始的 DDC 需要通過 3D 掃描器捕獲特定於人的模板。
我們的方法只需要 SMPL 模型,並以 SMPL 模型作為輸入進行了比較(DDC with SMPL),並提供了具有特定於人模板的原始DDC結果作為參考。
如 Figure 8 所示,DDC對於具有特定於人的模板工作得很好,但是變形粗糙的SMPL網格更具挑戰性,導致變形幾何上的人工物,如頭部。

- 與 Textured Neural Avatar (TNA) 的關係:
- 由於 TNA 的代碼和數據不可用,僅從概念上討論與該工作的區別。
- 與我們的方法不同,TNA 無法合成人類的動態外觀。
- 此外,他們的結果不具有視圖一致性,並且經常因缺失的身體部分等人工物而受到影響(見補充視頻)。
Ablation Study#
D1 上進⾏了 ablation study 並在每 10 幀的四個測試視圖上進⾏評估。
Effect of Texture Features#

- 在本篇方法中,每個採樣點都與從其最近表面點的2D紋理映射中提取的紋理特徵連接,作為預測殘差變形和動態外觀的條件。
- 比較了三種情況:
- w/o texture:既不提供紋理也不提供提取的紋理特徵。在這裡,我們使用姿勢向量作為條件。
- w/o feature extractor (raw texture inputs):對2D紋理映射不執行特徵提取,即使用最近表面點的紋理顏色作為條件。
- w/o texture w/ normal (normal map inputs):我們在法向圖上提取高維特徵並使用特徵作為條件。
- 發現相比於壓縮的姿勢向量,2D texture map 包含更多空間信息,如姿勢依賴的局部細節。此外,特徵提取器可以編碼局部和全局信息,從而實現更好的質量。
- 還觀察到直接從法向圖中提取特徵會產生非常差的結果。這是因為整個法向圖可以表示姿勢信息,而法向圖上的單個像素不提供任何信息。
Effect of Geometry-guided Deformation#
- SMPL模型用作3D代理以分離 inverse kinematic transformations 和 residual non-rigid deformations 的效果進一步得到評估。
- 對比研究:
- 無殘留變形:在姿態空間中的空間點只通過逆向運動學變換轉換到標準空間。
- 無幾何指導:我們直接用變形網絡預測全部運動。

- 如 Fig.10 所示,將全部變形建模為 inverse kinematic transformations 和 residual non-rigid deformations 可以獲得最好的質量。
- 直接學習全部變形不是有效的,因此會產生嚴重的 artifacts。
Sparse Inputs#

- 通過稀疏的訓練相機和訓練幀作為輸入來測試我們的方法。
- 具體設計了兩種實驗設置:
- 使用5個均勻分布在上半球的訓練相機。
- 在包含19,500幀的訓練序列中均勻抽樣195個訓練幀。
- 如 Fig.11 所示,我們的方法即使在稀疏輸入下也不會遭受顯著的性能下降。
Limitations#
無法處理如裙子這樣的寬鬆服裝。
無法忠實地生成手指 (Fig.12)。

- 由於手部未被跟踪,SMPL 手是打開的,而 GT 手通常是拳頭,這導致手部生成的 GT 紋理中存在嚴重的 noise。
- 即使使用改進的人體模型(如SMPL-X),由於在整個身體圖像中手部圖像的低解析度,準確跟踪手勢仍然具有挑戰性。
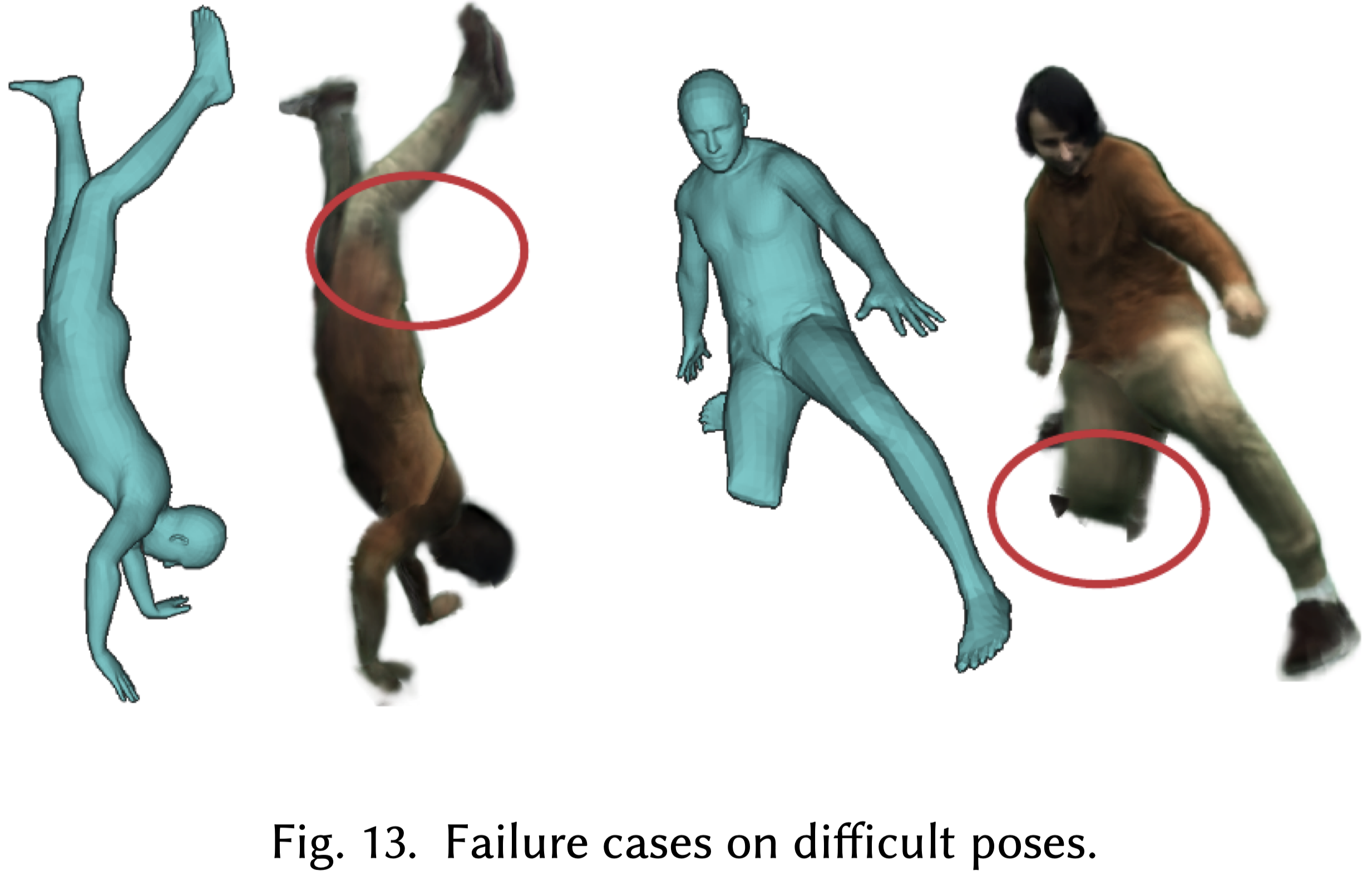
雖然我們的方法可以很好地推廣到具有挑戰性的未見姿勢,但當姿勢與訓練姿勢完全不同,或者當存在過度的關節彎曲時,可能會失敗 (Fig.13)。
Conclusion#
- 提出 Neural Actor 方法,針對任意視角和姿勢合成高保真人物角色圖像。
- 利用參數化身體模型作為 3D 代理,解糾3D空間到 canonical space,並應用 NeRF 學習由姿勢和視角引起的幾何和外觀效果。
- 通過 2D texture map 作為潛在變量,預測殘留變形和動態外觀。
- 方法在渲染質量上超越現有技術,並可應對新姿勢和可控新形狀的合成。