
針對單眼影片的人體可動畫自由視角渲染,MonoHuman(CVPR 2023)提出 shared bidirectional deformation,在 canonical space 共享運動權重並以前向/反向一致性正則,學得 pose‑independent 變形場,減輕單向變形在不可見姿態上的 over‑fitting;同時構建以關鍵影格為索引的 observation bank,透過 forward correspondence search 從相似姿態檢索對應特徵以引導渲染,緩解遮擋與細節模糊。該方法於新視角與新姿態設定皆優於既有方法(LPIPS 顯著提升),並能在複雜極端姿勢下保持外觀連貫與細節保真。
論文資訊
- Link: https://arxiv.org/abs/2304.02001
- Conference: CVPR 2023
Introduction#
- Animating Virtual Avatars
- 對於 VR 和數位娛樂至關重要。
- 之前的方法:使用 NeRF 進行重建,但存在動作連貫性問題或依賴於特定姿勢的表示。
- MonoHuman Framework
- 設計用於在新的姿態下渲染高品質的 avatars。
- 利用:
- Bi-directional constraints 和關鍵幀信息來保持連貫性。
- Shared Bidirectional Deformation 進行 pose-independent deformation。
- Forward Correspondence Search module,使用關鍵幀特徵來指導渲染。
- Challenges & Prior Works
- 傳統方法需要多視角影片並且有渲染限制。
- 挑戰包括 over-fitting、耗時的算法和依賴於 template model。
- 許多方法記住姿態並難以泛化到新姿態。
- MonoHuman’s Strengths & Contributions
- 旨在獲得 pose-independent deformation、 unified deformation directions 和 direct appearance referencing。
- 可以從任何視點/姿態渲染人類。
- 在測試中優於現有方法。
Related Works#
- Human Performance Capture
- 傳統方法:使用多視角視頻 [9,42,53] 或深度相機 [29,41,55,58] 重建人體。
- 表面網格的反照率地圖重建 [12,13]。
- 近期趨勢:以輻射場 [6,17,20等] 或距離功能 [47, 54] 表示人類幾何。
- NeuralBody [34]:使用 SMPL [26] 結構化姿態特徵。
- 限制:主要用於室內多攝像機設置。
- Human Rendering from Monocular Video
- 目標:繞過多視角限制。
- 方法:
- 從單張圖像重建靜態人體 [38, 39, 52]。
- 使用單眼視頻變形預掃描的人體模型 [14, 56]。
- 使用自旋視頻重建整個人體 [1]。
- SelfRecon [16]:以學習性非剛性運動和 SMPL 蒙皮表示身體運動。
- 使用可變形的 NeRF 進行人體動態表示 [32,33,37]。
- 挑戰:深度模糊和姿態觀察不足導致過度適應。
- 解決方案:引入運動先驗來規範變形 [17,50,51]。
- 重點:進行自由視點的人體渲染;這項工作的目的是將頭像動畫化為新姿態。
- Human Animation
- Neural Actor [24]:從 UV 空間的可變形 NeRF 並用預測的紋理地圖進行細節精煉。
- 通過姿態相依的潛在代碼創建可動畫模型 [34]。
- 通過轉換點到本地骨坐標驅動標準模型 [30,43]。
- Moco-Flow [4]:使用時間條件的前向變形網絡。
- 問題:許多方法記住姿態並難以泛化到新姿態。
- 基於圖像的渲染
- 目標:合成新視角圖像,不需要詳細的 3D 幾何。
- 傳統方法:從光場插值獲得新視角圖像 [8, 10]。
- 現代方法:代理幾何和深度地圖推斷 [2,36]。
- 深度學習的進步:引入學習組件以增強渲染 [7,15,18, 等]。
- IBRNet [48]:學習圖像特徵的混合權重。
- NeuRay [25]:預測 3D 點對輸入視圖的可見性。
Methods#
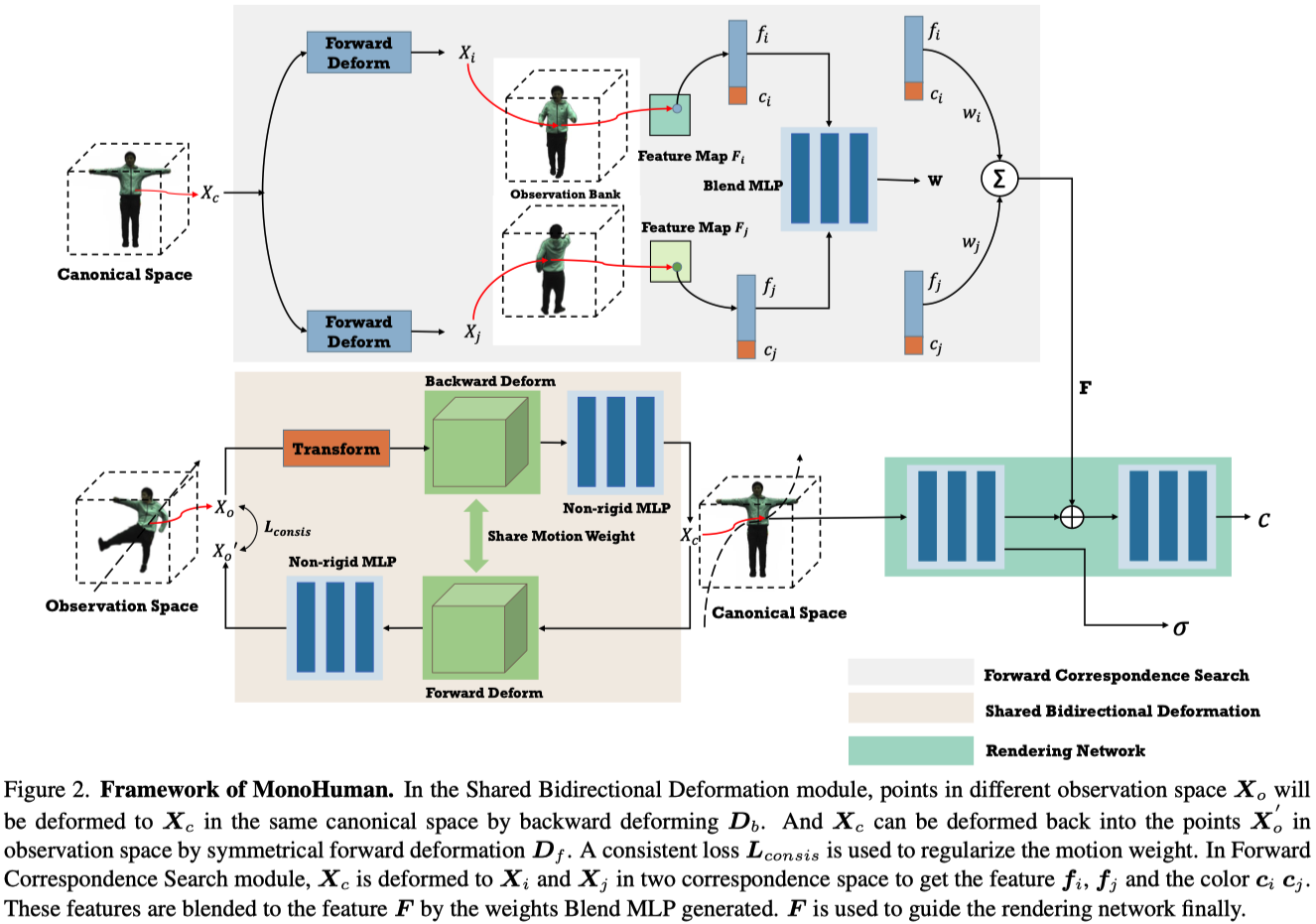
Preliminaries and Problem Setting#
$$ (\mathbf{c}(\mathbf{x}_\mathbf{o}), \sigma(\mathbf{x}_\mathbf{o})) = F_c(D(\mathbf{x}_\mathbf{o}, \mathbf{p})), \tag{1} \label{eq:1} $$| 符號 | 描述 |
|---|---|
| $D$ | backward deformation 映射函數,輸入身體姿勢 $\mathbf{p}$ 與觀測空間中的點 $\mathbf{x}_\mathbf{o}$,輸出 canonical space 中的點 $\mathbf{x}_\mathbf{c}$ |
| $F_c$ | 映射網路,輸入 canonical space 中的點 $\mathbf{x}_\mathbf{c}$,輸出其顏色值 $c$ 與密度 $\sigma$ |
Shared Bidirectional Deformation Module#
HumanNeRF 所提出的 single backward deformation 僅受到 image reconstruction loss 的約束,這樣的約束是不夠的,並且當遇到看不⾒的姿勢時會獲得更多的變形誤差。(Sec. 4 中會證明)
直觀上,僅在 deformation field 中定義 loss 有助於規範 deformation field,然而如何建立有效的約束並非易事,例如:
- MoCo-Flow [4] 使⽤額外的 time-conditioned forward deformation MLP 來約束變形的⼀致性。
- BANMo [57] 使⽤不同的 MLP 來產⽣ pose-conditioned deformation weights,以實現前向和後向變形。
然⽽,由於 deformation field 是兩個「不同」的 MLP 並且為 frame-dependent or pose-dependent,因此它們仍然存在 over-fitting 問題。
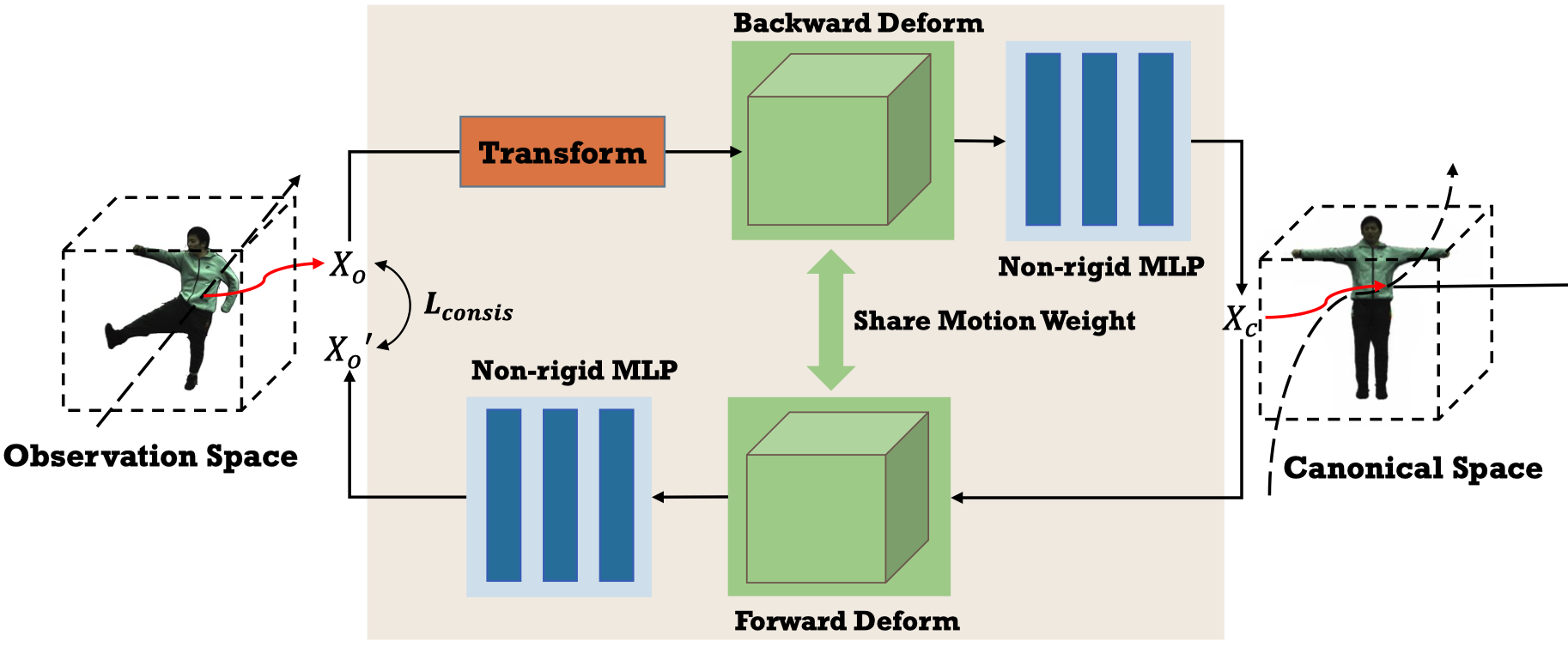
在本篇中,作者設計了 Shared Bidirectional Deformation module,該模組利用在 canonical space 中定義的相同運動權重進行前向和反向變形。
在實作中,作者將 backward deformation 表示為 Eq.\ref{eq:2}:
$$ D_b : (\mathbf{x}_\mathbf{o}, \mathbf{p}) \rightarrow \mathbf{x}_\mathbf{c}, \tag{2} \label{eq:2} $$| 符號 | 描述 |
|---|---|
| $\mathbf{p} = \{ \omega_i \}$ | 以軸角向量表示的 $K$ 個關節旋轉 |
Following HumanNeRF 的方法,完整的 deformation 由兩部分組成:motion weight deformation 與 nonrigid deformation:
$$ D_b(\mathbf{x}_\mathbf{o}, \mathbf{p}) = T^{\text{b}}_{mo}(\mathbf{x}_o, \mathbf{p}) + T^{\text{b}}_{NR}(T^{\text{b}}_{mo}(\mathbf{x}_\mathbf{o}, \mathbf{p})), \tag{3} \label{eq:3} $$$T^{\text{b}}_{mo}$ 的計算與 linear blend skinning 相近:
$$ T^{b}_{mo}(\mathbf{x}_\mathbf{o}, \mathbf{p}) = \sum_{i=1}^{K} w^i_o(\mathbf{x}_\mathbf{o}) (R_i\mathbf{x}_\mathbf{o} + t_i), \tag{4} \label{eq:4} $$| 符號 | 描述 |
|---|---|
| $w^i_o$ | 第 $i$ 根骨頭的 blend weight |
| $R_i, t_i$ | 將骨頭座標從 observation space 轉換到 canonical space 的旋轉與平移 |
Motion weight 的計算都與 HumanNeRF 相同 (Eq.\ref{eq:5} 與 Eq.\ref{eq:6}),詳細內容請參考 HumanNeRF。
$$ w^i_o(\mathbf{x}_\mathbf{o}) = \frac{w^i_c(R_i\mathbf{x}_\mathbf{o} + t_i)}{\sum_{k=1}^{K} w^k_c(R_k\mathbf{x}_\mathbf{o} + t_k)}, \tag{5} \label{eq:5} $$$$ W_\mathbf{c}(\mathbf{x}_c) = \text{CNN}(\mathbf{x}_\mathbf{c}; \mathbf{z}), \tag{6} \label{eq:6} $$接著,本篇作者額外使用定義在 canonical space 中的 motion weight 來實現 forward deformation:
$$ D_f : (\mathbf{x}_\mathbf{c}, \mathbf{p}) \rightarrow \mathbf{x}_\mathbf{o}, \tag{7} \label{eq:7} $$與 backward deformation 不同,因為 motion weight 是定義在 canonical space 上,因此 forward motion weight 可以通過 $\mathbf{x}_\mathbf{o}$ 直接查詢:
$$ T^f_{mo}(\mathbf{x}_\mathbf{c}, \mathbf{p}) = \sum_{i=1}^{K} w^i_c(\mathbf{x}_\mathbf{c})\mathbf{x}_\mathbf{c}, \tag{8} \label{eq:8} $$對於 non-rigid deformation,作者使用另一個 MLP 來計算 forward deform。前向與後向 deformation 可以以相同的方式表示成 Eq.\ref{eq:9}:
$$ T_{NR}(\mathbf{x}, \mathbf{p}) = \text{MLP}_{\text{NR}}(T_{mo}(\mathbf{x}, \mathbf{p}), \mathbf{p}), \tag{9} \label{eq:9} $$為了添加只與 deform field 相關的限制作為正規化,作者直覺的使用前向和反向變形一致性 $\text{L}_{\text{consis}}$如 Eq.\ref{eq:10}:
$$ \text{L}_{\text{consis}} = \begin{cases} d & \text{if } d \geq 0 \\0 & \text{else}\end{cases}\quad \text{where } d = L_2(\mathbf{x}_\mathbf{o}, D_f(D_b(\mathbf{x}_\mathbf{o}, \mathbf{p}),\mathbf{p})), \tag{10} \label{eq:10} $$| 符號 | 描述 |
|---|---|
| $L_2$ | $L_2$ 距離計算,僅懲罰距離大於閾值 $\theta$ 的點 |
我的問題是既然 $x_o$ to $x_c$ 是 skeletal + non-rigid,為什麼他的 $x_c$ to $x'_b$ 不是先把 non-rigid 去除掉,再 inverse 回去?
此外,由於他使用的 forward non-rigid motion MLP 跟 backward 不一樣,等於說他只是為了做 consistency loss,白白 train 了一個對於推論階段完全用不到的 MLP
Forward Correspondence Search Module#
首先,作者設計了一個 observation bank,包含了對應特徵以指導渲染過程。他們通過拓展時間,並在這些由輸入單眼視頻序列的關鍵幀圖像中搜索對應特徵,來構建一個 observation bank。
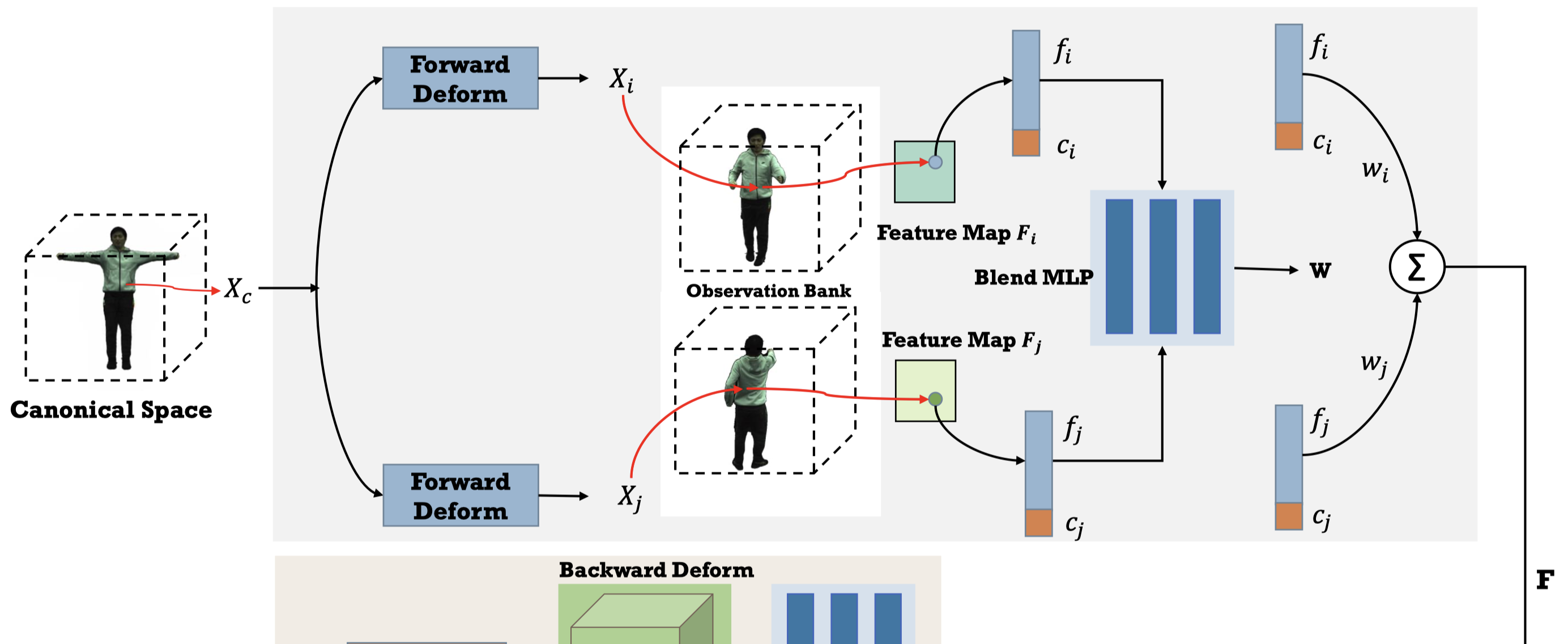
他會將影片中的 frame 按照 pose 的骨盆角度分成兩組,人體的正面與反面。
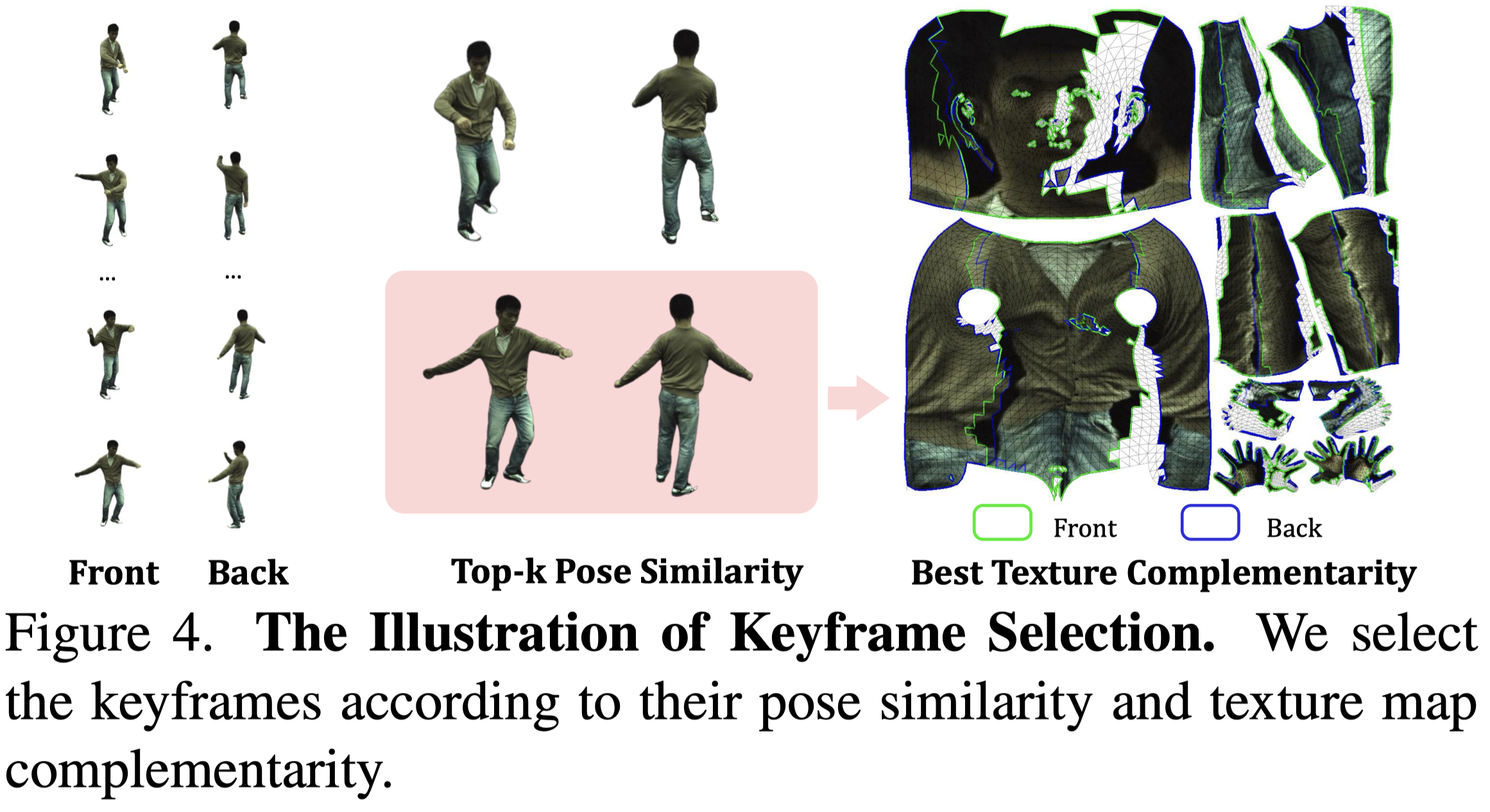
從兩組姿勢中,按照姿勢的相似程度,將最相近的兩個 frames 組成一對,總共 k 對。
接著從 canonical space 採樣一個點 $\mathbf{x}_\mathbf{c}$,將其映射到 observed space 中,因為有正反兩面(其實是兩個不同的 frame),因此會對應到兩個 observed space 中的點 $\mathbf{x}^i_\mathbf{o}$ 與 $\mathbf{x}^j_\mathbf{o}$ 。
$$ \mathbf{x}^i_\mathbf{o} = D_f (\mathbf{x}_\mathbf{c}, \mathbf{p}_\text{i}), \tag{11} \label{eq:11} $$符號 描述 $\mathbf{p}_\text{i}$ 第 $i$ 幀的姿態 根據相機參數,把 $\mathbf{x}_\mathbf{o}$ 投影到相機視圖座標上得到 $\mathbf{x}_\text{i}$ 與 $\mathbf{x}_\text{j}$。
$$ \mathbf{x}_\text{i} = K_i E_i \mathbf{x}^\text{i}_\mathbf{o}, \tag{12} \label{eq:12} $$符號 描述 $K_i, E_i$ 第 $i$ 幀的相機內外參數 $\mathbf{x}_\text{i}$ 第 $i$ 幀中的像素位置,用於取樣影像的特徵 $f_i$ 與顏色 $c_i$ 作者使用 IBRNet 中的 U-Net 架構做為 feature extractor,輸入 RGB image 與相機視圖座標 ($\mathbf{x}_\text{i}$ 與 $\mathbf{x}_\text{j}$),並獲得對應的 feature ($f_i, f_j$)與 color ($c_i, c_j$)。(這步驟是猜的,文章中簡單帶過,補充資料也沒寫)
作者將 $f$ 與 $c$ concatenate ,並使用 Blend MLP 來獲得對應的 blend weight。(Eq.\ref{eq:13b})
$$ \mathbf{w} = \text{MLP}_\text{blend}((f_i;c_i), (f_j;c_j)), \tag{13b} \label{eq:13b} $$通過 Eq.\ref{eq:13a} 可以得到在 canonical space 中查詢的 $\mathbf{x}_\mathbf{c}$ 對應的 feature $\mathbf{F}$。
$$ \mathbf{F} = w_i(f_i;c_i) + w_j(f_j;c_j), \tag{13a} \label{eq:13a} $$$\mathbf{F}$ 會被送入 Rendering Network 中去 guide 顏色輸出。
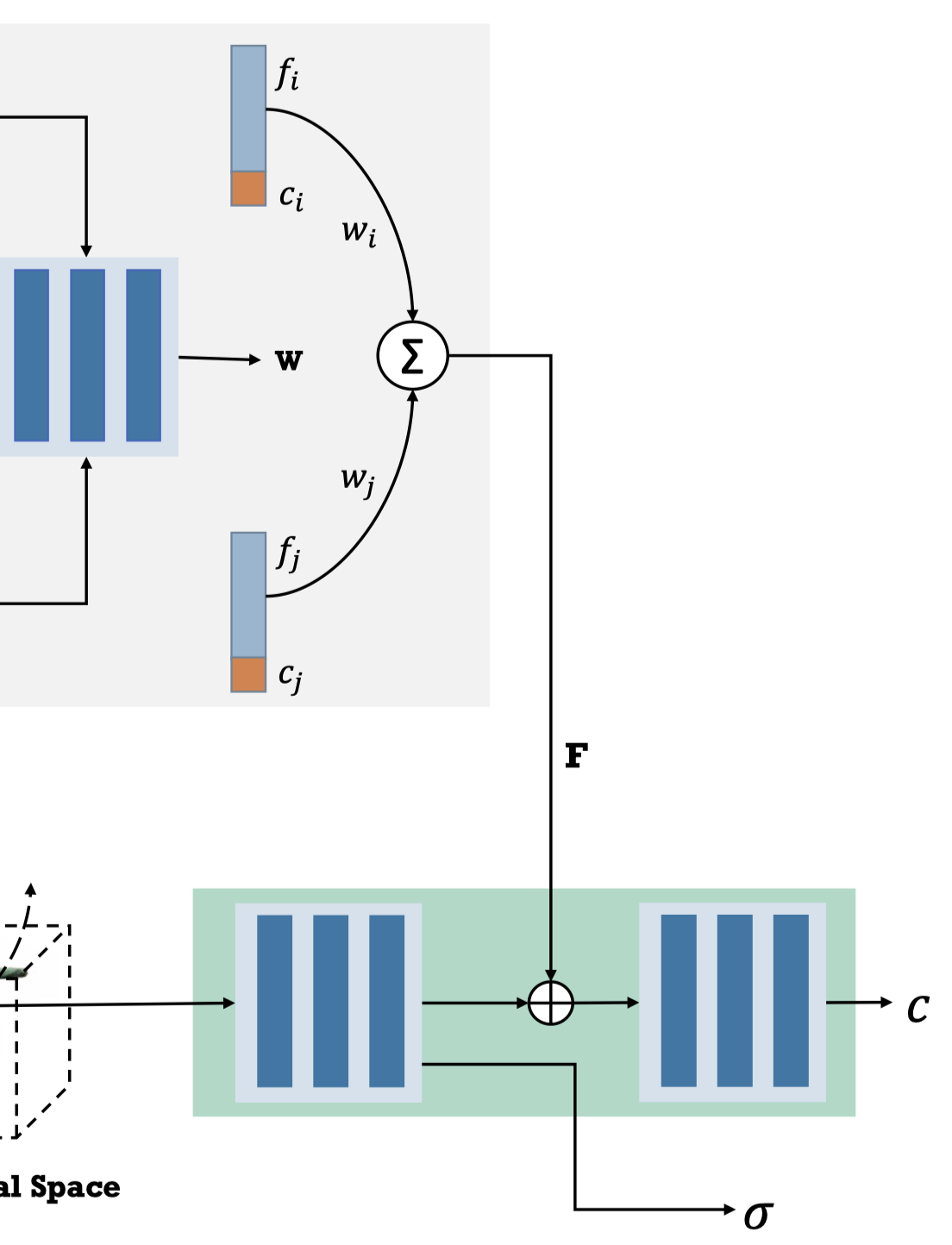
從第四步驟開始我就不是很懂了,問題點:
- 他生成的 blend weight 跟 Shared Bidirectional Deformation Module 中,motion weight deformation 使用到的 SMPL 的 blend weight 有什麼不一樣?
- Eq.\ref{eq:13b} 用來描述 Blend MLP 我能理解,但上式是怎麼計算的,其中的 $\mathbf{w}_i$ 又是什麼鬼?
- 訓練過程中,這個 Observation Bank 裡的資料是要全部走過一次,還是挑姿勢接近的做?能想像,如果要全部走過一次應該會超級花時間
Volume Rendering and Network Training#
Volume rendering with deformation#
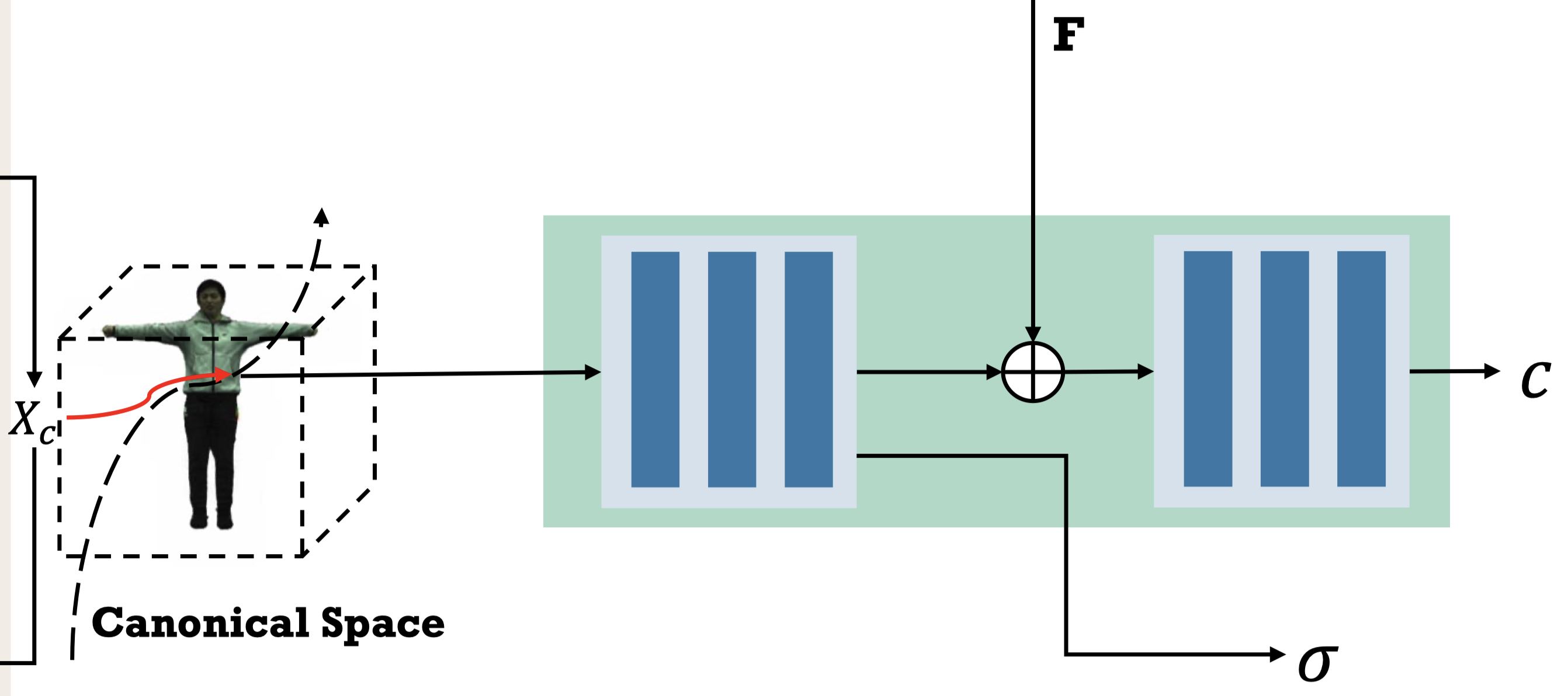
Rendering Network 表示為一個映射 $F_r$:
$$ \mathbf{c}(\mathbf{x}_\text{i}), \sigma(\mathbf{x}_\text{i}) = F_r(\gamma(\mathbf{x}_\text{i}), \mathbf{F}), \tag{14} \label{eq:14} $$| 符號 | 描述 |
|---|---|
| $\gamma$ | $\mathbf{x}_\text{i}$ 的 sinusoidal positional encoding |
最後,透過 volume rendering equation 來渲染這個 neural field。
具有 $D$ 個 samples 的射線 $\mathbf{r}$ ,其最終顏色 $C(\mathbf{r})$ 可以表示為 Eq.\ref{eq:15}:
$$ \begin{align*} C(\mathbf{r}) &= \sum_{i=1}^{D} \left( \prod_{j=1}^{i-1} (1 - \alpha_j) \right) \alpha_i \mathbf{c}(\mathbf{x}_\text{i}), \tag{15} \label{eq:15} \\ \alpha_i &= 1 - \exp(-\sigma(\mathbf{x}_\text{i}) \Delta t_i) \end{align*} $$| 符號 | 描述 |
|---|---|
| $\Delta t_i$ | 第 $i$ 與第 $i+1$ 個 samples 之間的間隔 |
Network training#
$$ \mathcal{L}_{\text{MSE}} = \sum_{r \in R} \left\| C(\mathbf{r}) - \hat{C}(\mathbf{r}) \right\|_2^2 \tag{16} \label{eq:16} $$$$ \mathcal{L} = \mathcal{L}_{\text{MSE}} + \lambda \mathcal{L}_{\text{LPIPS}} + \mathcal{L}_{\text{CONSIS}}, \tag{17} \label{eq:17} $$Experiments#
Experiment Settings#
- Datasets
- ZJU-MoCap
- 從網路蒐集的 in-the-wild 影片
- Preprocessing
- 使用 PARE [19] 估計相機矩陣與人體姿態
- 使用 RVM [23] 取得分割遮罩
- 選取關鍵影格作為 Forward Correspondence Search Module 的輸入
- Comparison Baseline
- NeuralBody
- HumanNeRF
- NeuMan
- Metrics
- PSNR, SSIM, LPIPS
- 整體框架在單張 V100 GPU 上訓練 70 小時
Quantitative Evaluation#
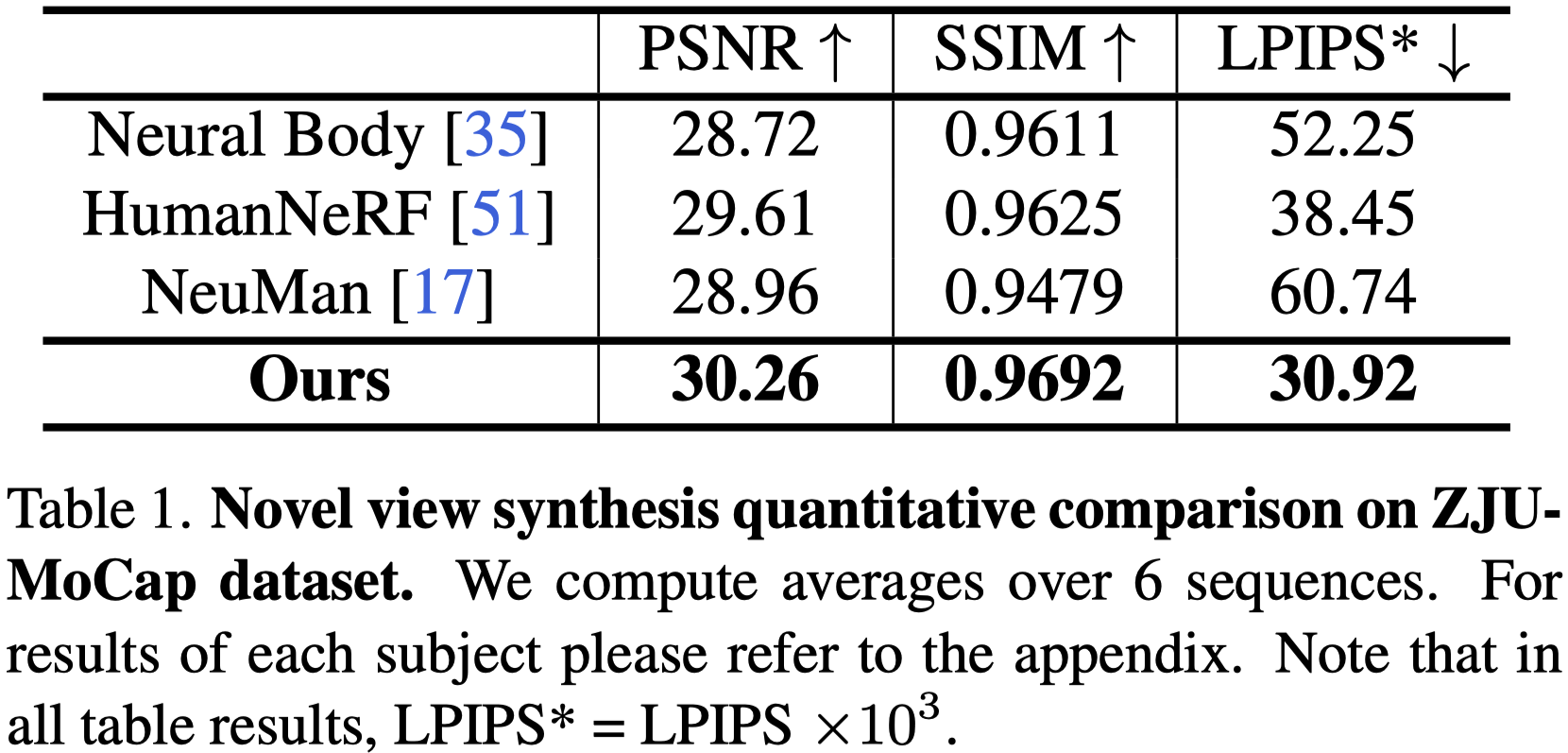
Novel View
Novel Pose
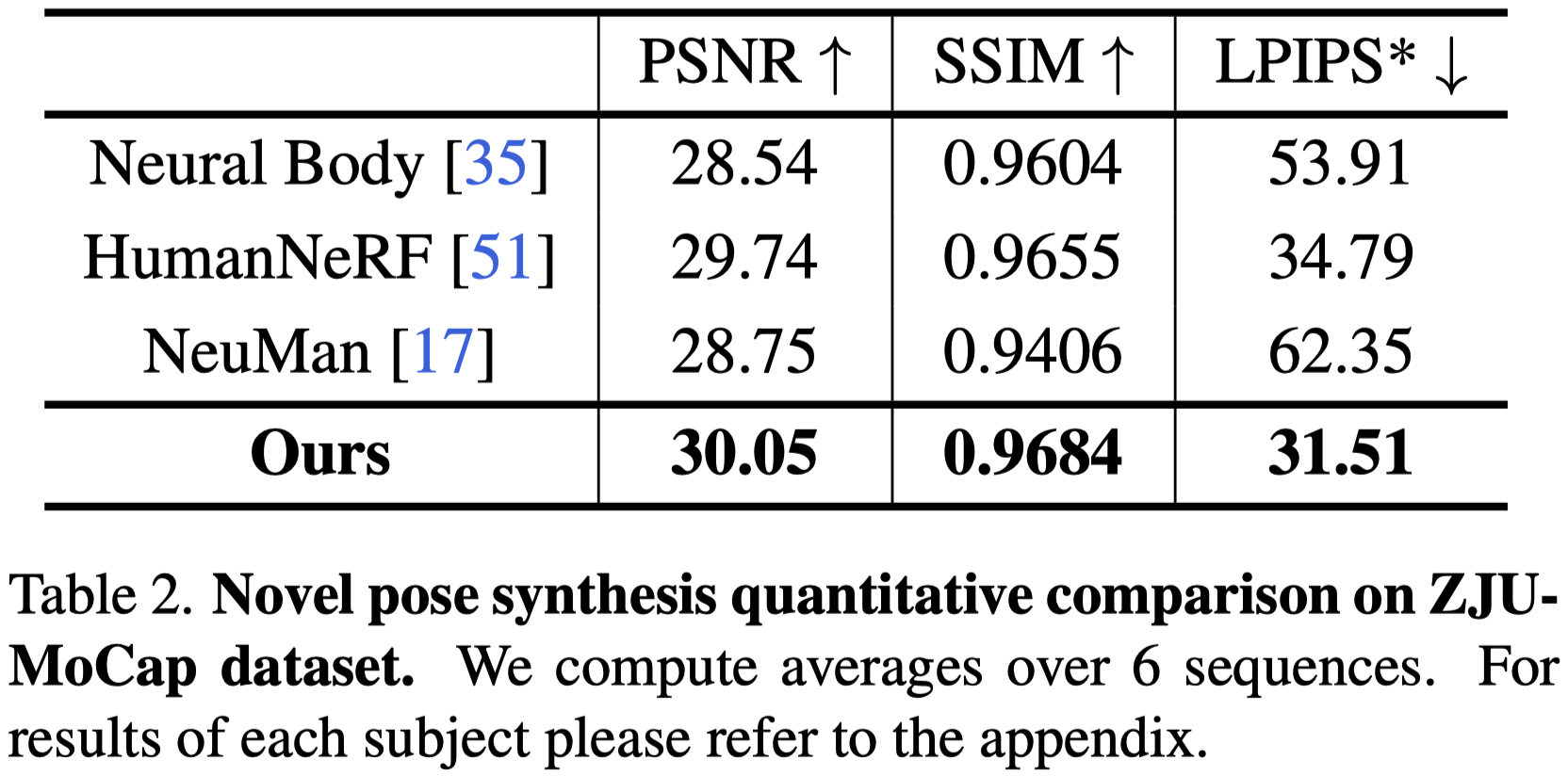
在新視角和新姿勢設置中的性能指標:
增強現實感技術:
- 利用對應特徵和變形場的一致限制有助於合成更真實的結果。
與 NeuralBody 的比較:
- 雖然具有不錯的PSNR 指標,但 NeuralBody 在新視角和新姿勢設置中都合成了視覺質量差的圖像。
- LPIPS 可以驗證 PSNR 傾向於平滑結果,可能會解釋這種差異。
與 HumanNeRF 的比較:
- 與 HumanNeRF 的 PSNR 改進不明顯,在新姿勢設置的主題 387 中略低。
- 然而,在 LPIPS 中看到了很大的改進,對於新視角和新姿勢設置分別有 19.6%和9.46% 的改進。
新姿勢合成的挑戰:
- 新姿勢合成比新視角合成更具挑戰性。
- 由於數據中的姿勢重複,一些評估指標異常,因此在分發姿勢中進行了提取定性比較。
與 NeuMan 的比較:
- NeuMan 僅在訓練期間更新 SMPL 參數,並將變形建模為最接近點的 LBS 重量,導致在新視角中的性能不佳。
Qualitative Evaluation#

- 視覺化新視角合成結果:
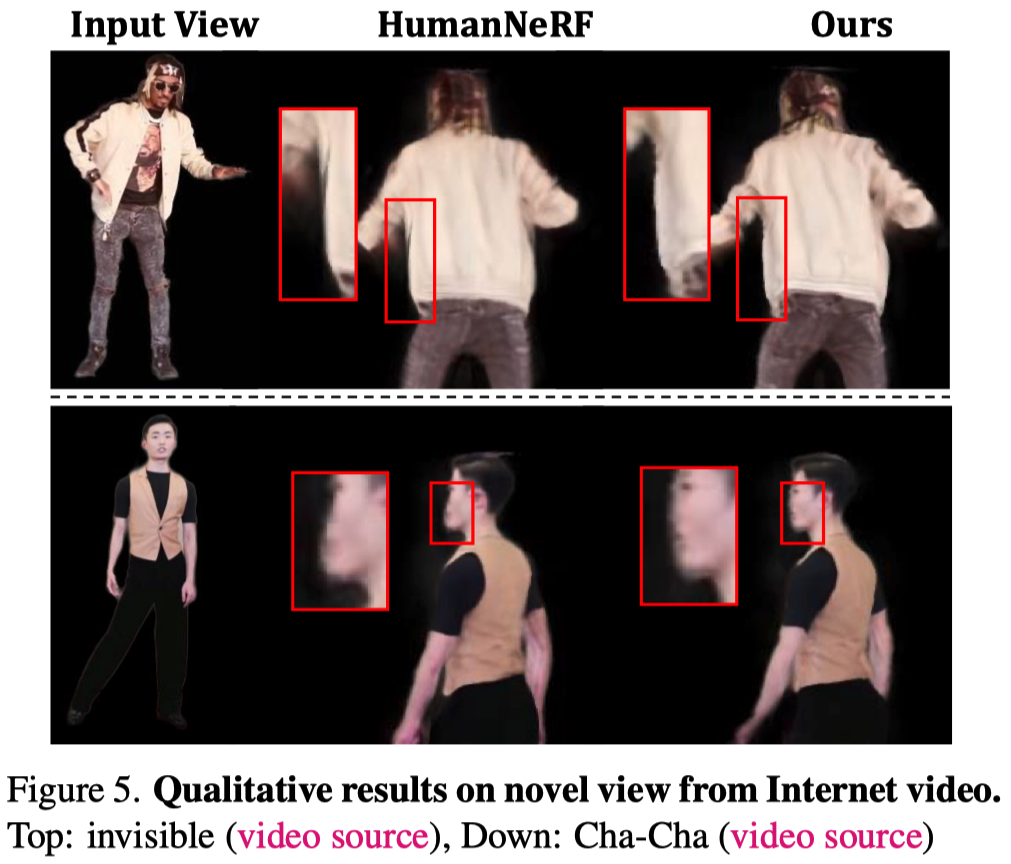

- 在複雜動作中評估動畫能力:
- ZJU-MoCap 和自收集視頻中的動作簡單且通常重複,因此需要在複雜動作中進行評估。
- 利用 MDM 模型生成背翻和武術姿勢序列等挑戰動作以進行動畫。
- 評估旨在為 HumanNeRF 和我們的方法重新構建的 avatar 進行動畫。
- 複雜動作的動畫結果(Fig.A8):
- HumanNeRF:在一些極端姿勢(例如,蹲下和高跳)中預測了多個 artifacts,並且在拳打動作和空中後翻姿勢中未能正確地變形手臂。
- 我們提出的 Shared Bidirectional Deformation Module:可以處理這些挑戰姿勢中的變形,並生成更真實的結果。
Ablation Study#
在 ZJUMoCap 數據集上對 Shared Bidirectional Deformation module 和 Forward Correspondence Search module 進行了 Ablation Studies。
分別在新視角和新姿勢設置中進行實驗,結果分別顯示在 Tab.3 和 Tab.4 中。
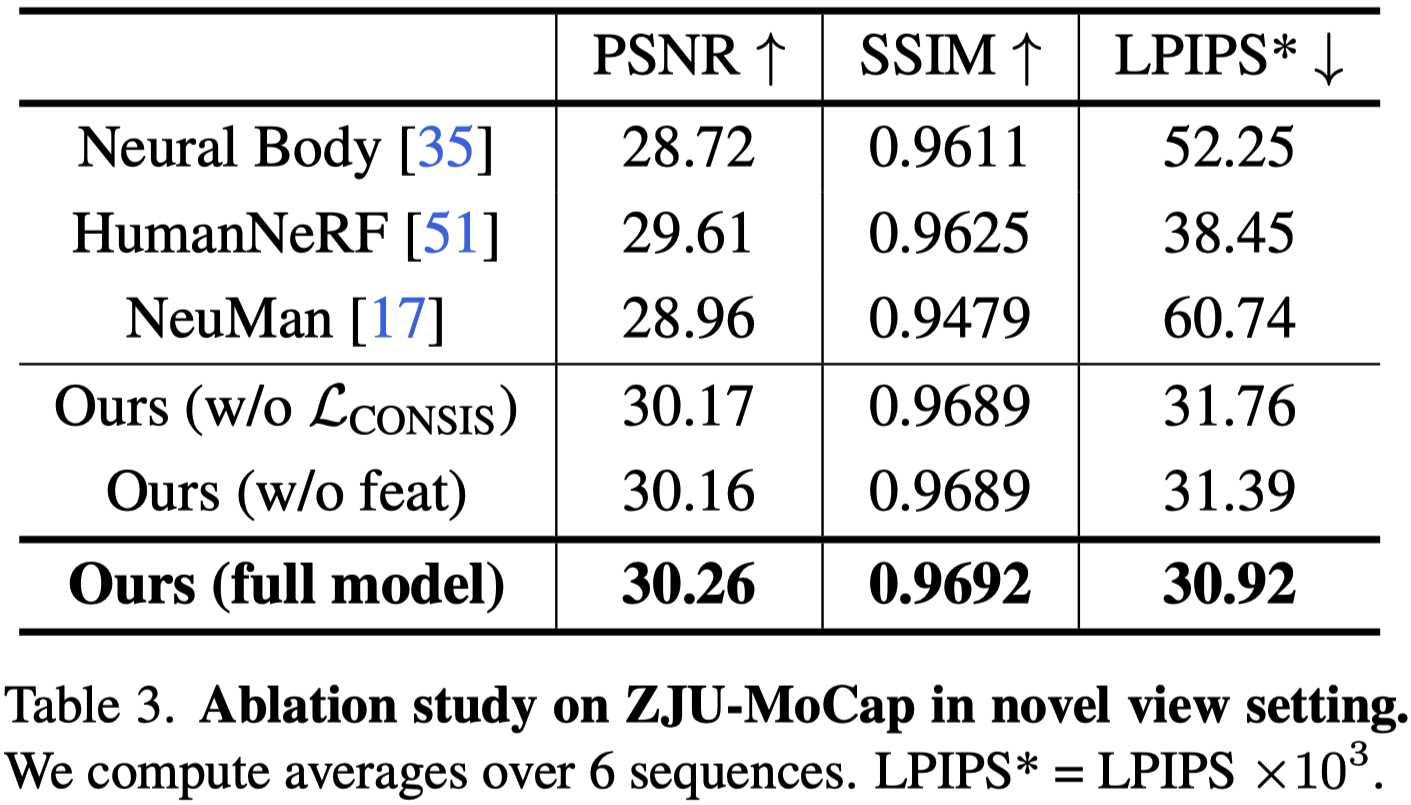
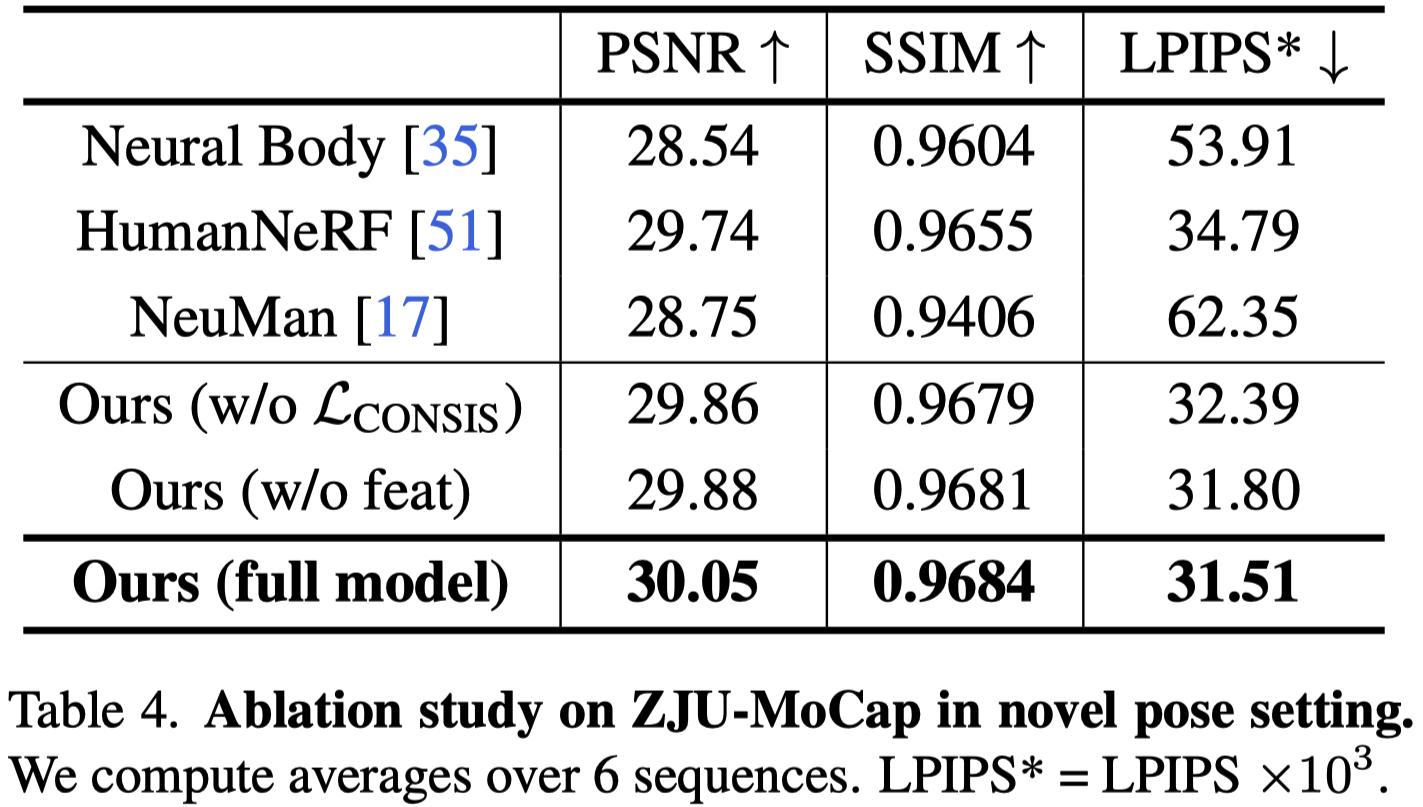
- 這兩個 modules 對結果的貢獻大致相同。
- 在新視角設置中,即使沒有 Consistency loss 限制,由於訓練數據中的輸入姿勢是熟悉的,所以變形大多是正確的。
- 在新的姿勢設定中,較高的 LPIPS 表示變形難度增加。
- 不正確的變形會影響透過 FCS moduel 搜尋的對應特徵,這使得產⽣的結果變得更糟。
Shared Bidirectional Deformation Module#

具有 Consistency loss 的 Shared Bidirectional Deformation Module 有助於產生更準確的變形,如 Fig.A3 中的手臂。如果沒有這種損失,⼿臂區域的變形往往會彎曲並產⽣明顯的 artifacts。
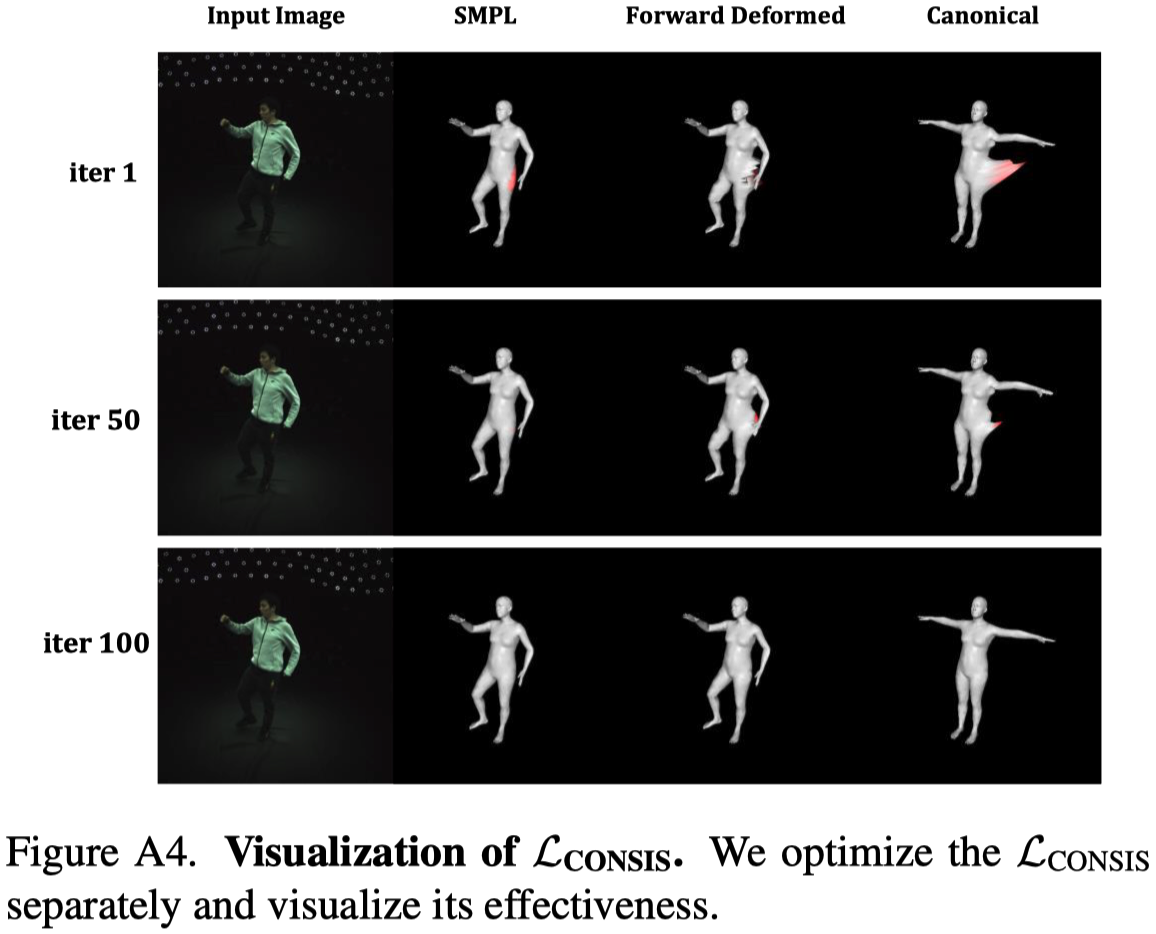
接著,作者將 SMPL vertex 作為輸入並優化。在 Fig.A4 中,可以看到經過 100 iterations 後,Forward Deformed 的結果與輸入的 SMLP vertex 接近,並且 canonical pose (T-pose) 也比較正常。由此證明 consistency loss 校正並正則化了 shared deformation weight。
他只有展示使用 consistency loss 時的可視化結果,因此實際上我們並不知道他這樣的設計是不是真的對於校正 canonical pose 有幫助。
Forward Correspondence Search Module#

Forward Correspondence Search Module 產⽣的對應特徵有助於在布料中產⽣更準確的顏⾊和紋理。
對他的實驗結果感到懷疑的同時,我去翻了一下我的實驗結果發現,MonoHuman 的表現一直都不如 HumanNeRF?訓練時間還更長,什麼鬼?
Conclusion#
- MonoHuman 簡介:我們提出了 MonoHuman,旨在穩健地以高保真度渲染出在新姿態下的視圖一致性虛擬角色。
- Shared Bidirectional Deformation Module:提出了一個新的 module,用於處理在分佈之外的新姿態下的變形。
- Forward Correspondence Search Module:用於查詢對應特徵,指導渲染網絡產生逼真的結果。
- Result:MonoHuman 在面對具挑戰性的新姿態設定時,仍能生成高保真度的圖像。
Limitations#
- **Dependency on Annotation Accuracy:**合成結果很依賴姿勢和遮罩標註的準確性。
- Case-Specific Training:我們的方法是專門針對一個人進行訓練的。如何讓這個方法適用於用單眼相機拍攝的不同人,是未來研究的一個重要方向。