
在 Immich 地理編碼優化專案的 v2.0 版本中,我引入了全新的 ETL (Extract-Transform-Load) 架構與 Registry 設計模式。本文將深入探討這些架構決策,並提供一份清晰的開發指南,說明如何利用這套架構快速擴充新的國家支援。
本專案旨在優化 Immich 的反向地理編碼功能,透過替換 GeoNames 原始的 cities500.txt 資料,解決中文翻譯不佳、臺灣行政區顯示不完整等問題。如果你還不熟悉這個專案,建議先閱讀本系列的專案介紹與使用教學 。
為什麼需要重構?v1.0 的痛點#
在 v1.0 版本中,處理邏輯高度耦合:
- 重複造輪子:每個國家的腳本都要自己處理座標轉換、檔案讀寫、錯誤處理。
- 輸出不一致:缺乏統一的 Schema,導致有些國家有
admin_3,有些則無,增加了後續處理的複雜度。 - 難以維護:所有邏輯擠在
main.py或散落的腳本中,新增一個國家需要修改多處代碼。
為了徹底解決這些問題,我在 v2.0 引入了 模組化 ETL 架構。
核心架構:ETL 模式與模組化設計#
v2.0 的核心設計理念是將地理資料處理標準化為 ETL (Extract-Transform-Load) 流程,並透過 GeoDataHandler 抽象基類實現模組化。
1. ETL 三階段流程#
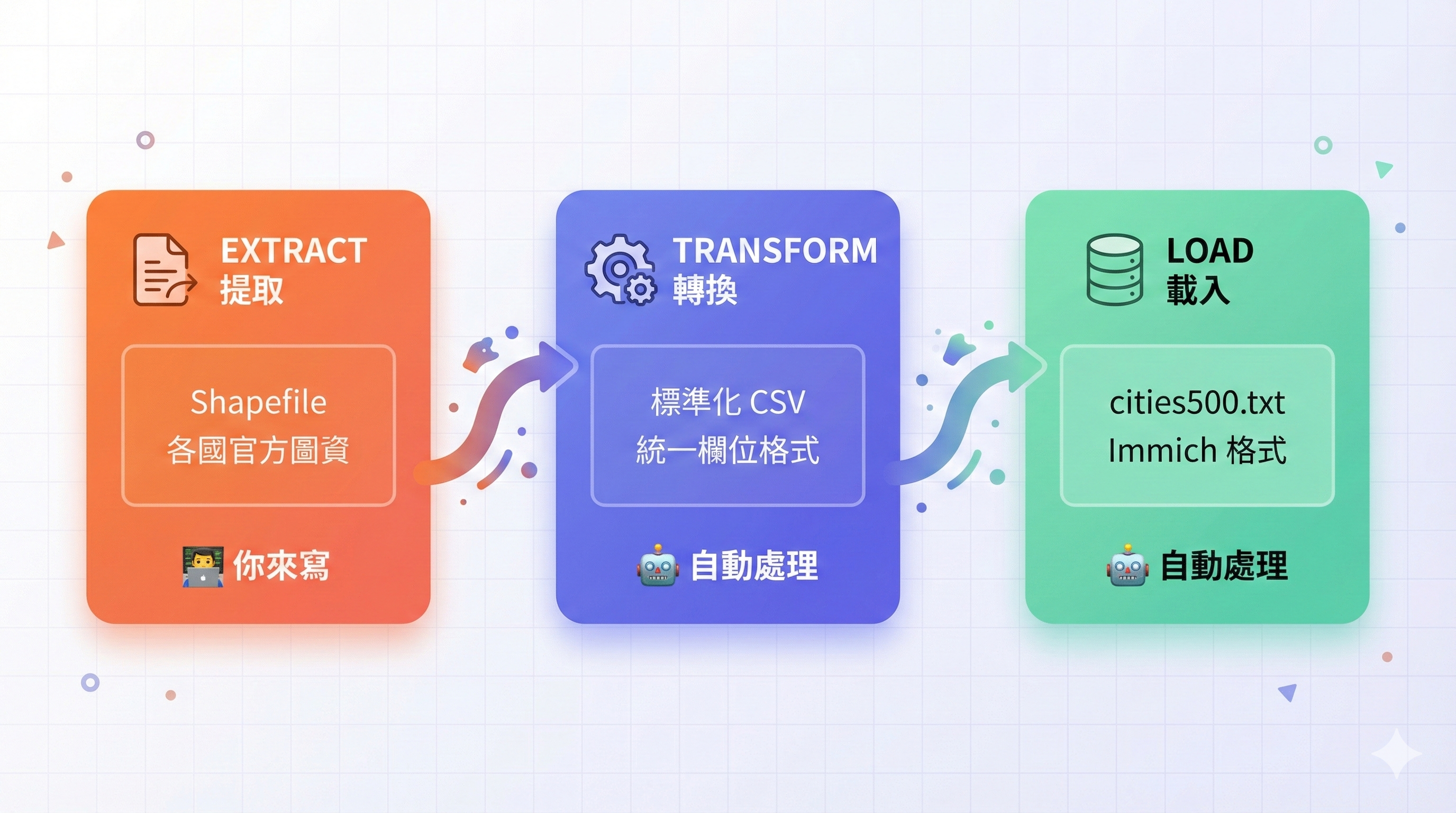
每個國家的資料處理都遵循相同的三階段流程:
| 階段 | 方法 | 說明 | 需要自訂? |
|---|---|---|---|
| Extract | extract_from_shapefile() | 從原始 Shapefile 提取資料,輸出標準化 CSV | ✅ 必須 |
| Transform | convert_to_cities_schema() | 將 CSV 轉換為 Immich 的 cities500 Schema | 通常不需要 |
| Load | replace_in_dataset() | 將處理後的資料合併回主資料集 | 通常不需要 |
- Extract:這是開發者主要需要實作的部分。每個國家的官方資料格式不同,需要撰寫客製化的提取邏輯。
- Transform:基類預設會執行標準轉換,包括自動偵測並分配不重複的
geoname_id(計算現有資料集中的最大 ID 並遞增,以避免衝突)、填入設定好的時區與國家代碼。若你的國家資料不需要額外的翻譯處理,則完全不需覆寫此方法,直接使用基類邏輯即可。 - Load:基類會根據
COUNTRY_CODE自動篩選並替換主資料集中對應國家的紀錄。除非你需要自訂合併策略,否則不需覆寫。
2. GeoDataHandler 抽象基類#
GeoDataHandler(定義於 core/geodata/base.py)採用 Template Method Pattern,將通用的流程固定下來,而將變動的邏輯留給子類實作。
這個基類處理了 80% 的髒活累活,讓開發者只需專注於該國特有的資料邏輯。
基類負責的共用邏輯 (base.py):
- 標準化輸出:
_save_extract_csv自動處理欄位排序、經緯度精度統一 (8位)、空值清理。 - ID 管理:
convert_to_cities_schema自動分配geoname_id,確保不與 GeoNames 官方 ID 衝突。 - 欄位映射:自動將 CSV 欄位對應到 Immich 需要的
cities500Schema。 - 錯誤處理:統一的 Logger 與 Exception 處理。
子類必須實作的方法:
class GeoDataHandler(ABC):
@abstractmethod
def extract_from_shapefile(self, shapefile_path: str, output_csv: str):
"""核心任務:從該國特有的 Shapefile 格式提取出標準 CSV"""
pass
# convert_to_cities_schema 通常不需要覆寫,除非有特殊需求3. 自動註冊機制 (Registry)#
本專案使用裝飾器 @register_handler 來實現工廠模式,讓系統能動態載入處理器。
# core/geodata/base.py
_HANDLER_REGISTRY = {}
def register_handler(country_code):
def decorator(cls):
_HANDLER_REGISTRY[country_code] = cls
return cls
return decorator這意味著新增一個國家時,完全不需要修改 main.py。只需新增一個檔案,系統就會自動識別。
開發指南:如何實作一個新的 Handler?#
如果你想為這個專案新增一個國家,你只需要關注一個檔案。以下是一個標準 Handler 的實作模板,展示了你需要填寫哪些部分。
實作模板#
在 core/geodata/ 下建立新檔案(例如 thailand.py):
from .base import GeoDataHandler, register_handler
import geopandas as gpd
import polars as pl
# 1. 使用裝飾器註冊 (必須與 ISO 3166-1 alpha-2 代碼一致)
@register_handler("TH")
class ThailandGeoDataHandler(GeoDataHandler):
# 2. 定義基本資訊
COUNTRY_NAME = "泰國"
COUNTRY_CODE = "TH"
TIMEZONE = "Asia/Bangkok"
def extract_from_shapefile(self, shapefile_path: str, output_csv: str):
"""
實作邏輯:
1. 讀取官方 Shapefile
2. 清理與轉換資料
3. 輸出標準 CSV
"""
# A. 讀取資料 (處理編碼問題)
gdf = gpd.read_file(shapefile_path, encoding="cp874")
# B. 座標轉換 (轉為 WGS84)
if gdf.crs.to_epsg() != 4326:
gdf = gdf.to_crs(epsg=4326)
# C. 資料清理與對應 (這是最需要客製化的部分)
# 假設官方欄位:PROV_T (省), AMP_T (縣)
df = pl.from_pandas(gdf).select([
pl.col("geometry").map_elements(lambda g: g.centroid.y).alias("latitude"),
pl.col("geometry").map_elements(lambda g: g.centroid.x).alias("longitude"),
pl.lit("泰國").alias("country"),
pl.col("PROV_T").alias("admin_1"), # 對應到第一級行政區
pl.col("AMP_T").alias("admin_2"), # 對應到第二級行政區
# 如果有更細的層級,繼續對應 admin_3, admin_4...
])
# D. 呼叫基類方法儲存 (自動處理排序、精度、格式驗證)
self._save_extract_csv(df, output_csv)開發重點提示#
- 專注於
extract_from_shapefile:這是你主要需要編寫程式碼的地方。你的目標是將各種奇形怪狀的官方資料,轉譯成包含latitude,longitude,country,admin_1… 的標準 DataFrame。 - 善用
_save_extract_csv:不要自己寫df.write_csv()。基類的_save_extract_csv會幫你處理很多細節(如確保座標精度統一為 8 位小數、全欄位排序以利版控),確保產出的檔案符合專案規範。 - 註冊即生效:寫完後,只需在
core/geodata/__init__.py中匯入這個新模組,CLI 工具就會自動抓到它。
# 驗證指令
# 1. 執行 Extract 階段 (產生 meta_data/th_geodata.csv)
python main.py extract --country TH --shapefile data/thailand.shp
# 2. 執行 Transform & Load 階段 (整合並輸出 cities500_optimized.txt)
python main.py enhance --country-code TH透過這種高度模組化的設計,貢獻者不需要理解整個 ETL 流程的複雜度,只需扮演好「翻譯官」的角色,將該國的資料翻譯成專案的通用語言即可。