
每當你上傳一張照片到 Immich,系統就會像魔法般自動標註拍攝地點——「台北市信義區」、「東京都澀谷區」。這背後並非雲端 API 的功勞,而是一套完全離線運行的逆地理編碼(Reverse Geocoding)系統。
但問題來了:Immich 官方使用的 GeoNames 資料庫,中文地名品質參差不齊,甚至有許多地點根本沒有中文名稱。這就是 immich-geodata-zh-tw 專案誕生的原因——透過一條精心設計的資料處理管線(Pipeline),將原始的 GeoNames 資料轉化為高品質的繁體中文地理資料庫。
本文將帶你深入這條 Pipeline 的每個環節,從資料下載、清理、增強、翻譯到最終打包,看看如何用 Python 和 Polars 處理超過 20 萬筆地理資料,讓你的 Immich 相簿擁有最精準的中文地名。
為什麼可以「替換」Immich 的地理資料?#
要理解 immich-geodata-zh-tw 的運作原理,我們得先搞清楚 Immich 的反向地理編碼是怎麼運作的。答案很簡單:Immich 完全依賴離線資料庫,而不是呼叫雲端 API。這意味著,只要我們提供更好的資料檔案,就能直接提升地名的品質。
Immich 啟動時會匯入哪些檔案?#
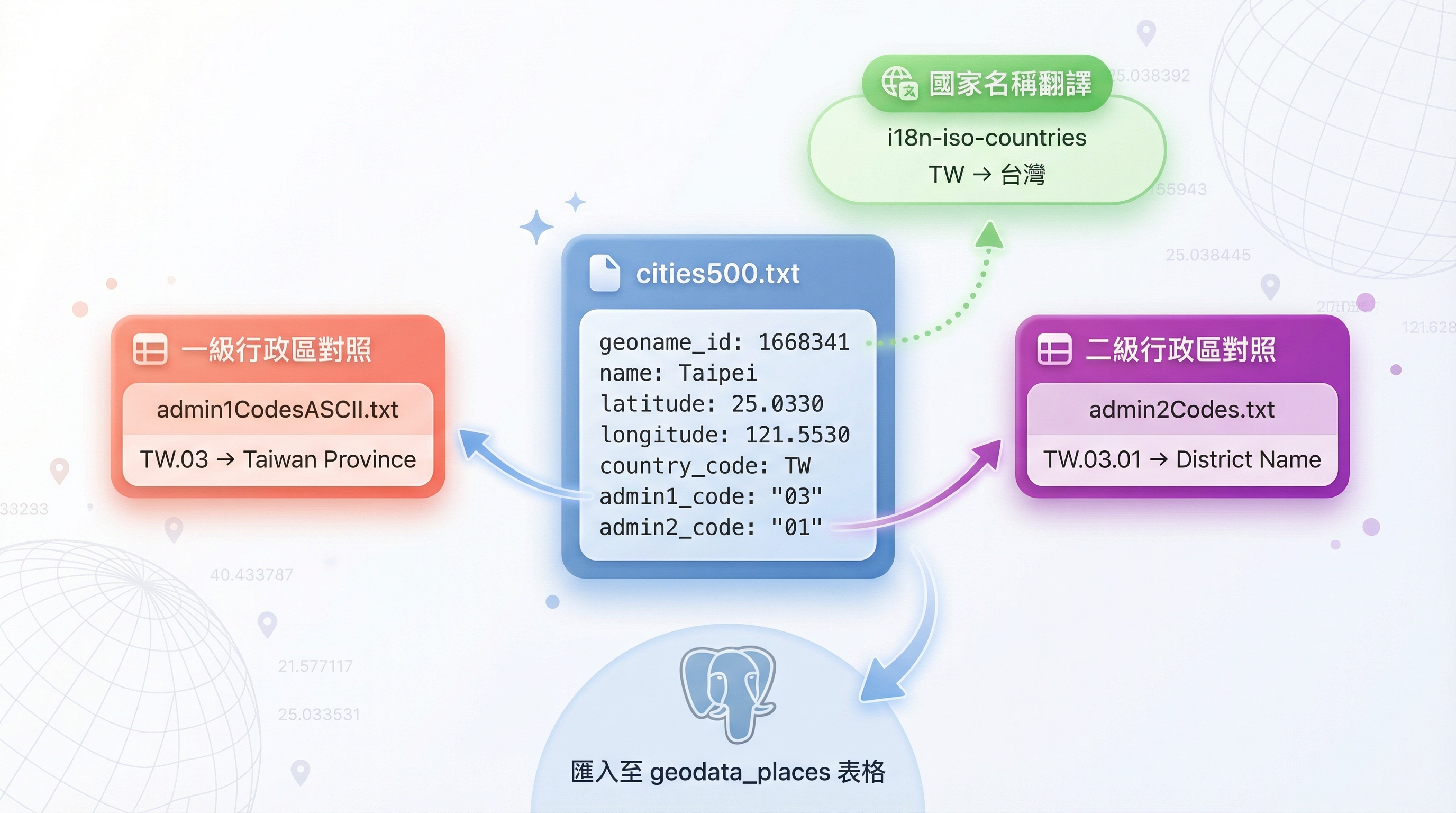
Immich 的地理資料全部來自 GeoNames,這是一個開放的地理資料庫,收錄了全球超過 1100 萬個地理點位。當 Immich 容器啟動時,會自動將以下檔案匯入 PostgreSQL:
1. admin1CodesASCII.txt - 一級行政區名稱對照
格式:國家代碼.行政區代碼 TAB 名稱 TAB ASCII名稱 TAB geoname_id
例如:
TW.03 Taiwan Province Taiwan Province 1668284這個檔案用於將 cities500.txt 中的 admin1_code 轉換為實際的行政區名稱。
2. cities500.txt - 核心的地理座標資料庫
這是 Immich 反向地理編碼的「心臟」——包含全球約 20 萬個人口超過 500 人的地點。檔案採用 Tab 分隔格式(TSV),每一行代表一個地理位置點,包含 19 個欄位:
geoname_id name asciiname alternatenames latitude longitude feature_class feature_code country_code cc2 admin1_code admin2_code admin3_code admin4_code population elevation dem timezone modification_dateImmich 會將這些資料匯入 PostgreSQL 的 geodata_places 表格,並使用 PostGIS 擴充建立空間索引。查詢時,系統主要依賴 latitude、longitude 定位最近的地點,然後從 name、country_code、admin1_code 等欄位組合出完整的地址。
3. i18n-iso-countries/langs/en.json - 國家名稱對照
Immich 使用這個檔案將國家代碼(如 TW)轉換為國家名稱。需要注意的是,Immich 固定讀取 en.json,即使你的介面語言設為繁體中文。
immich-geodata-zh-tw 利用這個特性,將 en.json 的內容替換為繁體中文(但 locale 仍保持 “en”),這樣 Immich 讀取時就會顯示「臺灣」而非「Taiwan」。詳細處理方式請見後文「Pipeline 之外:國家名稱翻譯」章節。
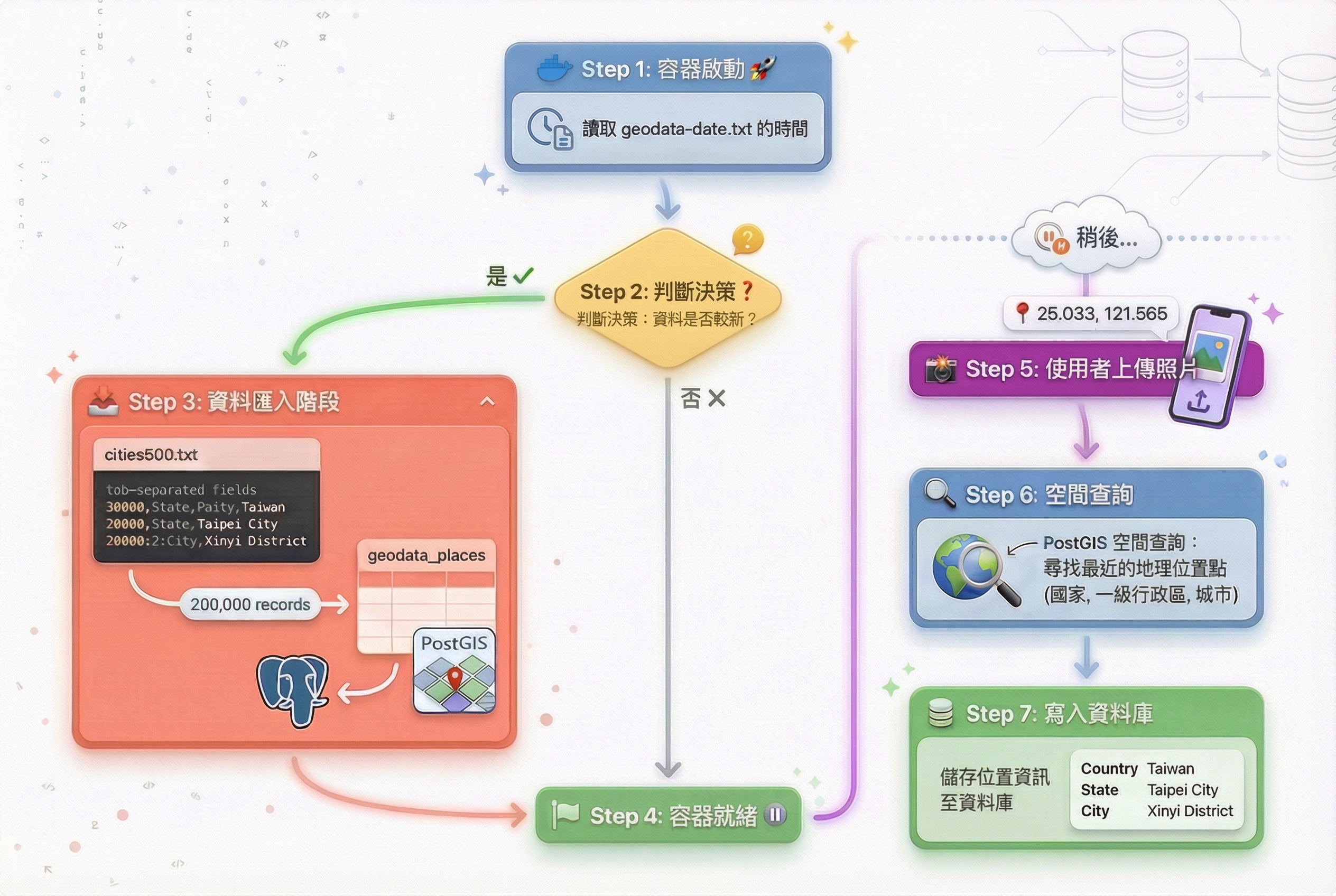
4. geodata-date.txt - 時間戳記檔案
這是一個單行文字檔,只包含一個時間戳。Immich 會比較這個檔案的修改時間與資料庫中的 reverse-geocoding-state,判斷是否需要重新匯入資料。
admin2Codes.txtadmin2Codes.txt 是二級行政區資料。Immich 雖然會下載,但實際上並不會在反地理編碼過程中使用,因此我們只需要保留該檔案以保持相同檔案結構,無需進行任何處理。
Immich 如何從座標找到地名?#
理解了資料結構後,關鍵問題來了:當你上傳一張帶有 GPS 座標(如 25.033, 121.565)的照片時,Immich 是如何從 20 萬筆資料中找出「台北市信義區」的?
答案是 PostGIS 空間索引 + 最近鄰查詢(Nearest Neighbor Query)。簡單來說,Immich 會:
- 將照片的經緯度轉換為 3D 球面座標
- 在
geodata_places表格中尋找距離最近的地點 - 提取該地點的 Country、Admin1、City 欄位
- 組合成最終的地址字串
這是 Immich 實際的查詢邏輯(簡化版):
// 簡化後的查詢邏輯
this.db
.selectFrom('geodata_places')
.selectAll()
.where(
sql`earth_box(ll_to_earth_public(${point.latitude}, ${point.longitude}), ${reverseGeocodeMaxDistance})`,
'@>',
sql`ll_to_earth_public(latitude, longitude)`,
)
.orderBy(
sql`(earth_distance(ll_to_earth_public(${point.latitude}, ${point.longitude}), ll_to_earth_public(latitude, longitude)))`,
)
.limit(1)您可以在 Immich 的官方 GitHub 倉庫中查看這段邏輯:map.repository.ts
關鍵函式說明:
ll_to_earth_public(lat, lng):將經緯度轉換為 3D 球面座標(基於地球橢球模型)earth_box(point, radius):建立以該點為中心、指定半徑的搜尋範圍earth_distance():計算兩點間的實際球面距離
這個查詢會先用 earth_box 縮小搜尋範圍,再用 earth_distance 精確排序,最後返回距離最近的那一筆資料。
掌握了查詢邏輯,就能「動手腳」#
看完 Immich 的查詢邏輯,你會發現一個關鍵事實:整個反向地理編碼系統完全依賴 cities500.txt 和相關檔案的內容。Immich 不會去驗證地名是否正確,也不會聯網查證資料——它只是單純地「找最近的點,讀取欄位值」。
這意味著,我們可以:
- 增加資料密度:在
cities500.txt中加入更細緻的地點(如台灣的村里、日本的町丁目) - 改善地名品質:將
name欄位從英文替換為精準的繁體中文 - 優化翻譯邏輯:處理簡繁轉換、異體字統一等問題
這正是 immich-geodata-zh-tw 的核心策略:透過一條資料處理管線,將 GeoNames 的原始資料轉化為優化版本,然後替換掉 Immich 預設的檔案。
六階段 Pipeline:從原始資料到繁體中文的旅程#
現在進入本文的核心:immich-geodata-zh-tw 如何將 GeoNames 的原始資料轉化為高品質的繁體中文地理資料庫?
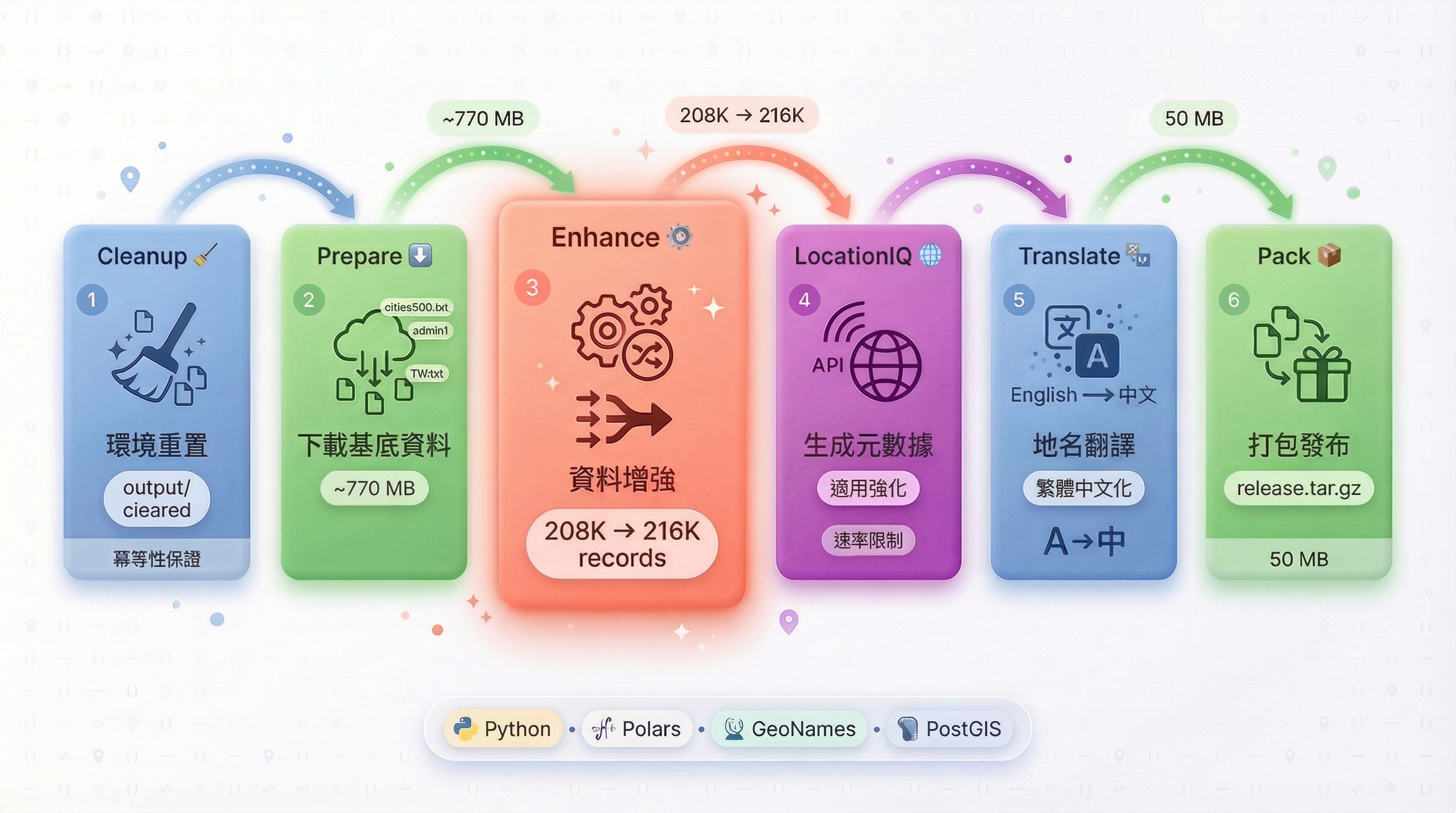
答案是一條六階段的資料處理管線(Pipeline)。你可以透過一行命令執行完整流程:
python main.py release --country-code TH這行命令會依序執行 Cleanup → Prepare → Enhance → LocationIQ → Translate → Pack 六個階段,從下載原始資料到最終打包,全自動完成約 20 萬筆地理資料的處理。
讓我們逐一拆解每個階段的職責,看看資料是如何一步步被轉化的。
階段 1:Cleanup — 冪等性的保證#
第一個階段很簡單:清空 output/ 目錄。
你可能會想:「這有必要嗎?」答案是:絕對必要。在資料處理流程中,殘留的舊檔案可能導致難以追蹤的bug。假設你上次執行在 Translate 階段中斷,output/cities500_translated.txt 只寫了一半——下次執行時,如果不先清理,Pack 階段可能會將這個不完整的檔案打包進去。
Cleanup 階段確保了 Pipeline 的冪等性(Idempotence):無論執行多少次,只要輸入相同,輸出就一定相同。這是資料處理系統最重要的特性之一。
階段 2:Prepare — 從 GeoNames 下載原料#
第二階段從 GeoNames.org 下載所有需要的原始資料,總共約 770 MB(含一個國家的完整資料):
| 檔案 | 用途 | 大小 |
|---|---|---|
cities500.txt | 全球 20 萬個主要地點 | ~35 MB |
admin1CodesASCII.txt | 一級行政區對照表 | ~144 KB |
admin2Codes.txt | 二級行政區對照表(保留但不使用) | ~2.2 MB |
{COUNTRY_CODE}.txt | 特定國家的完整資料(依參數動態下載) | 視國家而定 |
alternateNamesV2.txt | 多語言地名對照表 | ~712 MB |
ne_10m_admin_0_countries.geojson | 國家邊界資料 | ~13 MB |
這裡有個重點:為什麼要下載完整的國家資料(如 TH.txt、US.txt 等)?
cities500.txt 只包含「人口 > 500」的地點,這對地理密度高的國家來說太粗糙了。以泰國為例,cities500.txt 可能只有幾百筆主要城市資料,但完整的 TH.txt 包含所有 GeoNames 收錄的泰國地點,我們可以從中篩選出更細緻的地理資訊。
這些檔案會根據 --country-code 參數動態下載。例如執行 python main.py release --country-code TH 時,系統會自動下載 TH.txt(泰國的完整資料)。
階段 3:Enhance — Pipeline 的心臟#
如果說 Pipeline 是一條生產線,Enhance 就是最核心的那台機器。這個階段要做的事情很複雜:
- 合併資料來源:將
cities500.txt(全球基底)與特定國家的 txt 檔案(如TH.txt)合併 - 去除重複點位:相同座標的地點只保留一筆
- 整合處理器資料:對於有國家處理器的國家(如台灣、日本、南韓),整合處理器預先產生的高品質資料
- 分配唯一 ID:確保所有新增資料都有不衝突的
geoname_id
最終結果:從 20 萬筆資料擴充到約 21.6 萬筆,並確保每一筆都是最高品質的記錄。
對於一些的國家(例如台灣、日本、南韓)我們希望提供更高品質的地理資料,並對地名進行優化,因此我們設計了 國家處理器(Handler) 模組。國家處理器是一個獨立的資料前處理模組,負責在 Pipeline 執行前就準備好高品質的國家專屬資料(例如台灣處理器從內政部 Shapefile 提取 7,000+ 個村里資料)。處理器的架構設計、實作細節和如何開發自訂處理器,將在下一篇系列文章《國家處理器架構與實作》中詳細說明。
在 Enhance 階段,Pipeline 會讀取這些處理器預先產生的資料檔案(如 meta_data/TW_geodata.csv),並將它們整合到最終的資料集中。
讓我們深入看看實作細節:
def update_geodata(cities_file, extra_files, output_file, min_population):
# 取得已註冊的處理器國家列表
handler_countries = get_all_handlers()
# 計算全域最大 geoname_id(避免 ID 衝突)
current_max_id = calculate_global_max_geoname_id()
# 先處理 admin1(一級行政區)
current_max_id = update_admin1_data(...)
# 再處理 cities500(城市資料)
current_max_id = update_cities500_data(...)3.1 ID 分配策略#
為了避免資料衝突和方便除錯,我們需為每筆新增的記錄分配唯一的 ID:
- 不會與 GeoNames 官方的 ID 衝突(使用 12,000,000+ 的範圍)
- 不同國家使用的 ID 範圍不重疊(每國分配 100 萬空間)
- 每筆記錄都有唯一的識別碼,便於追蹤和除錯
3.2 為什麼要先處理 Admin1?#
答案藏在 cities500.txt 的資料結構中:每筆地點資料都有一個 admin1_code 欄位(如 TW.03),這個代碼會參照 admin1CodesASCII.txt 來取得完整的行政區名稱(如「台北市」)。
如果我們不先處理 admin1,後續處理 cities500 時,行政區名稱就會是空的或不正確。這就像蓋房子一定要先打地基——admin1 就是 cities500 的「地基」。
3.3 Cities500 資料處理#
Cities500 的處理分為兩個步驟:
步驟 1:合併額外資料
def merge_extra_data(cities500_df, extra_files, min_population):
# 讀取 extra_data/{COUNTRY_CODE}.txt(如 TH.txt)
# 注意:TW/JP/KR 由 Handler 處理,不使用此流程
extra_df = pl.DataFrame(schema=CITIES_SCHEMA)
for file in extra_files:
if Path(file).exists():
extra_df = extra_df.vstack(
pl.read_csv(file, separator="\t", schema=CITIES_SCHEMA)
)
# 篩選:ID 不重複且人口數 >= min_population
filtered_extra_df = extra_df.filter(
~pl.col("geoname_id").is_in(cities500_df["geoname_id"])
& (pl.col("population") >= min_population)
)
# 合併
cities500_df = cities500_df.vstack(filtered_extra_df)去重邏輯
對於相同的 (latitude, longitude) 座標,系統會:
- 保留
population最大的那筆 - 如果人口數相同,保留
geoname_id最小的(優先使用官方 ID)
duplicates_check = cities500_df.group_by(["latitude", "longitude"]).agg(
pl.max("population").alias("population_max"),
pl.min("geoname_id").alias("geoname_id_min"),
)
cities500_df = cities500_df.join(
duplicates_check,
on=["latitude", "longitude"],
how="inner",
).filter(
(pl.col("population") == pl.col("population_max"))
& (pl.col("geoname_id") == pl.col("geoname_id_min"))
).select(cities500_df.columns)步驟 2:整合處理器產生的資料
對於有國家處理器的國家(如台灣、日本、南韓),系統會讀取處理器預先產生的高品質資料(存放在 meta_data/ 資料夾),並完全替換該國在 cities500 中的原始資料。這確保了這些國家的地理資料達到最高品質。
階段 4:LocationIQ — 為非 Handler 國家生成元數據#
對於沒有專屬 Handler 的國家(如泰國、美國、歐洲各國等),我們需要另一種方式來獲取精確的行政區劃資訊。這就是 LocationIQ 發揮作用的地方。
LocationIQ 的角色
LocationIQ 是一個基於 OpenStreetMap 資料的反向地理編碼 API 服務。給定座標(經緯度),它能返回該位置對應的詳細地理資訊,包括國家、州/省(admin_1)、市/縣(admin_2)、區/鎮(admin_3)、街道/社區(admin_4)等多層級行政區劃。
在 immich-geodata-zh-tw 中,LocationIQ 用於為這些非 Handler 國家生成高品質的元數據檔案(meta_data/{country_code}.csv),這些元數據會在後續的 Translate 階段被用來優化地名翻譯,包含提供翻譯名稱,同時也能起到修正 GeoNames 資料中可能不夠精確的行政區資訊的作用。(同一個座標 Geonames 可能因為偏差或細粒度不足,導致 admin1/admin2 欄位不正確)
def cmd_locationiq(args):
api_key = args.locationiq_api_key or os.environ.get("LOCATIONIQ_API_KEY")
generate_geodata_locationiq.set_locationiq_config(api_key, qps)
for cc in args.country_code:
logger.info(f"正在為 {cc} 生成元數據...")
generate_geodata_locationiq.process_file(
cities500_file,
output_file,
cc,
batch_size=100
)工作流程:
- 從
cities500_optimized.txt讀取指定國家的所有座標 - 對每個座標調用 LocationIQ API 進行反向地理編碼
- 解析 API 回傳的 JSON,提取
admin_1、admin_2、admin_3、admin_4等行政區資訊 - 儲存為
meta_data/{country_code}.csv,供 Translate 階段使用
多語言優化:
LocationIQ API 支援多語言查詢。專案中設定了語言優先級:
params = {
"accept-language": "zh,en", # 優先請求中文,備選英文
"normalizeaddress": 1,
"normalizecity": 1,
}這樣可以提高獲取中文地名的機率,但最終的繁體中文翻譯仍由 Translate 階段 負責處理(包括簡繁轉換、異體字統一等)。
使用限制:
由於 LocationIQ 是商業 API 服務,有 QPS(每秒查詢數)和總配額限制。因此這個階段:
- 通常只用於補強特定國家或地區的資料
- 不適合全球性的大規模使用
- 需要妥善管理 API Key 和查詢速率
階段 5:Translate — 三層翻譯策略#
資料增強完成後,我們擁有了更完整的地理資料,但大部分地名仍是英文或拼音。Translate 階段的任務就是:將這些地名轉換為精準的繁體中文。
但翻譯地名並不簡單。GeoNames 的資料品質參差不齊,有些地點有官方中文名,有些只有簡體中文,還有些完全沒有中文資料。為了應對這種複雜情況,我們設計了一套三層優先級翻譯機制:
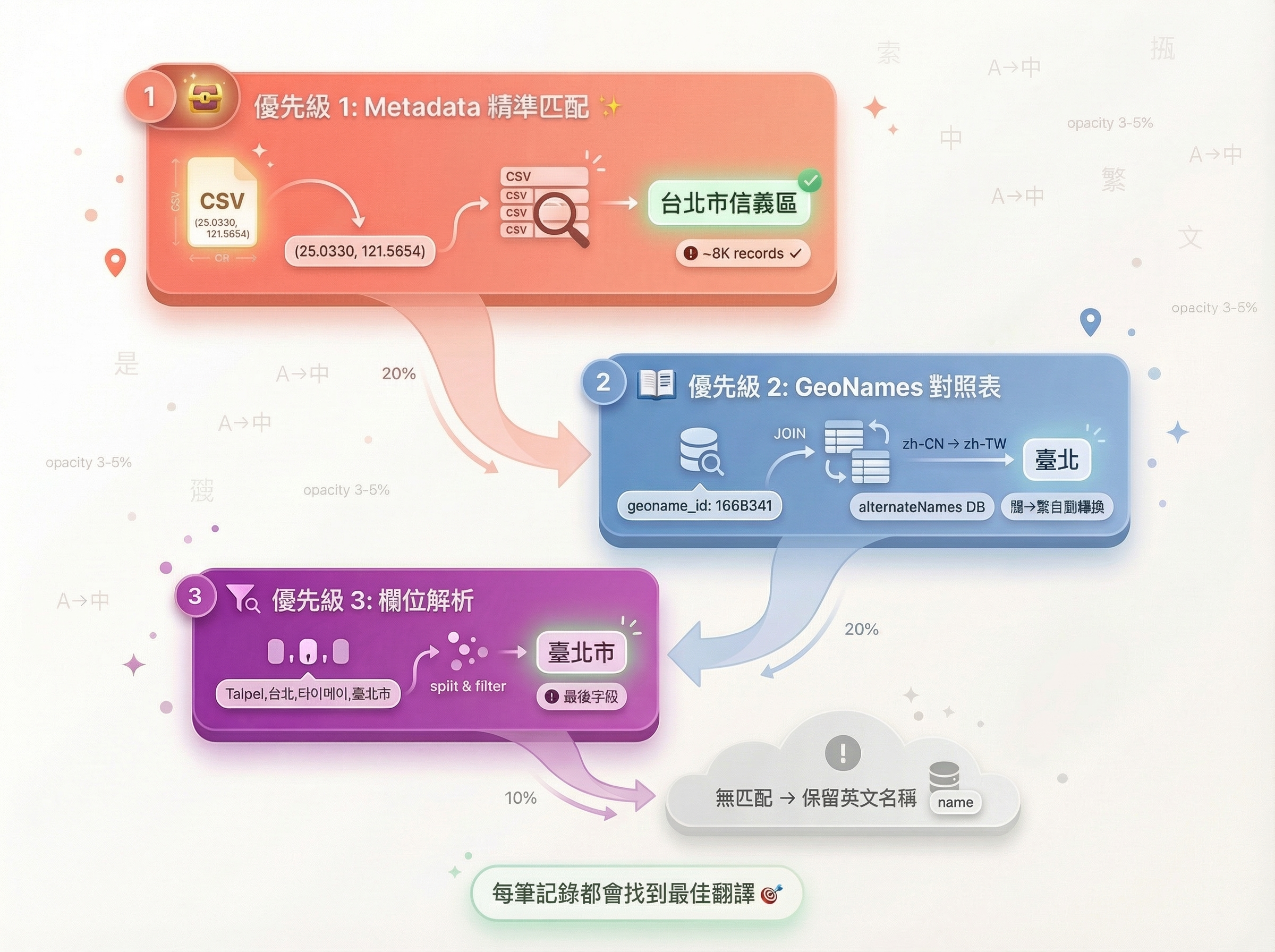
優先級 1:Metadata 精準匹配(最高品質)
第一層是「黃金標準」:透過 (latitude, longitude) 精確匹配 meta_data/ 資料夾中的高品質資料。這些 metadata 由國家處理器(例如從政府官方資料提取)或 locationiq 預先產生,確保地名的準確性。
def translate_from_metadata(row):
country = row["country_code"]
if country not in meta_data:
return None
result = meta_data[country].filter(
(pl.col("latitude") == row["latitude"]) &
(pl.col("longitude") == row["longitude"])
)
if not result.is_empty():
item = result["admin_2"].item()
if is_chinese(item):
return converter_s2t.convert(item) if is_simplified_chinese(item) else item
return None優先級 2:GeoNames 對照表(官方資料)
如果第一層沒有匹配,就透過 geoname_id 查詢 GeoNames 官方的多語言對照表(alternateNamesV2.txt,約 1500 萬筆翻譯)。這個資料庫包含了全球大部分地點的多語言名稱,品質也相當可靠。
cities500_df = cities500_df.join(alternate_name, on="geoname_id", how="left")優先級 3:欄位解析(最後手段)
如果前兩層都沒有結果,就解析 cities500.txt 本身的 alternatenames 欄位。這個欄位包含逗號分隔的多個名稱(如 "Taipei,台北,타이베이,臺北市"),我們會從中篩選出繁體中文,或將簡體中文轉換為繁體。
def extract_chinese_names(alt_names):
if not alt_names:
return None
candidates = alt_names.split(",")
# 優先返回繁體中文
for w in candidates:
if is_traditional_chinese(w):
return w
# 其次返回簡體中文(轉換為繁體)
for w in candidates:
if is_simplified_chinese(w):
return converter_s2t.convert(w)
return None最後,將三層結果合併:
cities500_df = cities500_df.with_columns(
pl.coalesce([
"translated_name", # Metadata 匹配
"alternate_translated_name", # Alternate Name
"alternatenames_translated", # Alternatenames 解析
]).alias("final_name")
)5.2 Admin1 翻譯#
Admin1 的翻譯相對簡單,主要透過 alternate_name 對照表:
df = df.join(alternate_name, on="geoname_id", how="left")
df = df.with_columns(
pl.when(pl.col("name_right").is_not_null())
.then(pl.col("name_right"))
.otherwise(pl.col("name"))
.alias("name")
)階段 6:Pack — 打包成 Production-Ready 的格式#
最後一個階段很簡單:將所有處理好的檔案打包成 Immich 可以直接使用的格式。
release/
├── geodata/
│ ├── cities500.txt ← 處理後的主要資料(繁體中文)
│ ├── admin1CodesASCII.txt ← 處理後的一級行政區
│ ├── admin2Codes.txt ← 原始的二級行政區(未修改)
│ ├── ne_10m_admin_0_countries.geojson ← 國家邊界
│ └── geodata-date.txt ← 時間戳(觸發 Immich 重新匯入)
├── i18n-iso-countries/
│ └── langs/
│ ├── en.json ← 內容已替換為繁體中文(Immich 讀取此檔)
│ └── zh-tw.json ← 繁體中文參考檔案(留存)
└── update_data.sh ← 一鍵更新腳本這個 tar.gz 檔案(約 50 MB)就是使用者在 GitHub Releases 下載的最終產物。解壓後直接覆蓋到 Immich 的資料目錄,重啟容器即可套用。
Pipeline 之外:國家名稱翻譯#
細心的讀者可能會發現,前面六個階段都在處理地名翻譯(城市、行政區),但國家名稱(如 TW → 臺灣)的翻譯在哪裡處理呢?
答案是:完全不在 Pipeline 中。
國家名稱翻譯採用了一個巧妙的 workaround,與 Pipeline 的動態處理邏輯完全無關。
Immich 的限制#
還記得文章開頭提到的嗎?Immich 固定讀取 i18n-iso-countries/langs/en.json 來顯示國家名稱,即使使用者介面語言設為繁體中文也一樣。這是 Immich 的架構設計,我們無法從外部改變這個行為。
理論上,這意味著國家名稱永遠只會顯示英文:Taiwan、Japan、South Korea。
聰明的 Workaround#
但我們可以「騙過」Immich:將 en.json 的內容替換為繁體中文。
{
"locale": "en", // ← locale 仍是 "en",Immich 看到這個就會讀取此檔
"countries": {
"TW": "臺灣", // ← 但內容已經是繁體中文了!
"CN": "中國",
"JP": "日本",
"KR": "南韓",
"US": "美國",
"GB": "英國"
// ... 總共 250 個國家的繁體中文名稱
}
}這樣一來,Immich 讀取 en.json 時,實際上會得到繁體中文的國家名稱。使用者在相簿介面看到的位置資訊就會是「臺灣 · 台北市 · 信義區」而非「Taiwan · Taipei City · Xinyi District」。
翻譯來源的權威性#
這 250 個國家的繁體中文譯名並非隨意翻譯,而是參考台灣政府官方資料:
- 中華民國外交部的官方國家名稱翻譯
- 經濟部國際貿易署的國家/地區代碼對照表
並經過微調優化,確保符合台灣慣用的稱呼。例如:
- 使用「臺灣」而非「台灣」(遵循政府正式用字)
- 使用「南韓」而非「韓國」(外交部官方譯名)
- 使用「阿拉伯聯合大公國」而非「阿聯酋」(經貿署正式名稱)
為何同時保留 zh-tw.json?#
你可能會好奇:既然 Immich 只會讀 en.json,為何專案中還有 zh-tw.json?
原因有三:
- 作為參考基準:
zh-tw.json保留了真正的繁體中文格式,方便未來維護和對照 - 未來擴充性:如果 Immich 未來支援依使用者語言動態切換國家名稱,我們已經準備好了
- 社群貢獻:其他開發者可能 fork 專案並修改 Immich 來支援多語言國家名稱
與 Pipeline 的關係#
國家名稱翻譯在 Pack 階段的處理非常簡單:
# 複製 i18n-iso-countries 目錄
shutil.copytree(
"i18n-iso-countries",
os.path.join(release_dir, "i18n-iso-countries")
)就只是單純複製整個 i18n-iso-countries/ 資料夾到 release 中,不涉及任何動態處理或翻譯邏輯。所有的「翻譯工作」都是在專案開發階段手動維護好的靜態 JSON 檔案。
這就是為何國家名稱翻譯完全獨立於 Pipeline 六階段之外——它不需要 Polars、不需要 GeoNames 資料、不需要任何動態處理,只是一個巧妙的靜態檔案替換策略。
Pipeline 的設計哲學#
在深入技術細節的同時,我們也不能忽略這套 Pipeline 的設計哲學。它體現了幾個關鍵原則:
1. 單向資料流(Unidirectional Data Flow)#
每個階段只依賴前一個階段的輸出,不會回頭修改已處理的資料。這種設計借鑑了函數式程式設計(Functional Programming)的理念,讓整個流程像一條清晰的管道,容易理解、測試和除錯。
如果你發現 Translate 階段的輸出有問題,只需要修改 core/translate.py 並重新執行這個階段,而不用擔心會影響前面的 Enhance 結果。
2. 模組化與可測試性(Modularity & Testability)#
每個階段都可以獨立執行,這對開發和測試非常有幫助:
python main.py prepare --country-code TW
python main.py enhance --min-population 100
python main.py translate開發時,你可以只執行需要測試的階段,而不用每次都跑完整個 Pipeline(可能需要 30 分鐘以上)。
3. 漸進式增強(Progressive Enhancement)#
Pipeline 設計成「失敗友好」的架構:即使某些階段失敗(例如 LocationIQ API 無法使用),依然能產出可用的資料,只是精度較低。這種設計確保了系統的韌性(Resilience)。
4. 明確的 ID 管理策略#
透過全域 ID 追蹤機制,確保:
- 新增的資料不會與官方資料 ID 衝突(使用 12,000,000+ 的 ID 範圍)
- 不同國家的資料使用的 ID 範圍不重疊(每個國家分配 100 萬 ID 空間)
- Admin1 和 Cities500 之間的參照關係保持一致
執行範例#
完整的 release 流程日誌:
$ python main.py release --country-code TW JP KR
[INFO] === 執行 cleanup 步驟 ===
[INFO] 清理完成。
[INFO] === 執行 prepare 步驟 ===
[INFO] 下載完成: geoname_data/cities500.txt
[INFO] geoname_data/admin1CodesASCII.txt 已存在,跳過下載。
[INFO] 地理名稱數據下載完成
[INFO] === 執行 enhance 步驟 ===
[INFO] 已註冊的 Handler 國家: TW, JP, KR
[INFO] 初始全域最大 geoname_id: 12534982
[INFO] 開始處理 admin1CodesASCII.txt
[INFO] 為 TW admin1 計算的 base_geoname_id: 12534983
[INFO] TW admin1 使用的 ID 範圍: 12534983 - 12535004
[INFO] 已更新 TW 的 admin1 資料
[INFO] admin1CodesASCII.txt 更新完成
[INFO] 開始更新 cities500.txt
[INFO] 成功新增 1247 行數據到 cities500.txt
[INFO] 處理重複座標完成,移除了 89 筆資料
[INFO] 為 TW 計算的 base_geoname_id: 12535005
[INFO] 已使用 TW Handler 替換 cities500 資料 (ID 範圍: 12535005 - 12542876)
[INFO] cities500.txt 更新完成 (208456 筆資料)
[INFO] === 執行 translate 步驟 ===
[INFO] 開始翻譯 output/cities500_optimized.txt
[INFO] 未翻譯的地名數量: 15234
[INFO] 已翻譯 cities500,結果已儲存至 output/cities500_translated.txt
[INFO] 翻譯文件已儲存至 output/admin1CodesASCII_translated.txt
[INFO] === 執行 pack 步驟 ===
[INFO] 打包完成: release.tar.gz
[INFO] 所有步驟完成!資料規模與效能#
實際測試數據(M1 MacBook Air, 8GB RAM):
| 階段 | 處理時間 | 輸入規模 | 輸出規模 |
|---|---|---|---|
| Prepare | ~30s | 網路下載 | ~200 MB |
| Enhance | ~15s | 208,000 筆 | 216,000 筆 |
| LocationIQ | ~30min* | 1,000 座標 | 1,000 筆 |
| Translate | ~20s | 216,000 筆 | 216,000 筆 |
| Pack | ~5s | 200 MB | 50 MB (壓縮) |
* 取決於 API QPS 限制(預設 2 QPS)
從原始資料到高品質中文地名的完整旅程#
讀到這裡,你已經完整理解了 immich-geodata-zh-tw 如何將 GeoNames 的原始資料轉化為高品質的繁體中文地理資料庫。讓我們回顧一下這條 Pipeline 的精髓:
Cleanup 確保了冪等性,讓每次執行的結果都一致。
Prepare 從 GeoNames 下載了約 770 MB 的原始資料。
Enhance 整合多個資料來源,從 20 萬筆擴充到 21.6 萬筆,並整合國家處理器預先產生的高品質資料。
LocationIQ 透過 API 補充特定區域的行政區資訊。
Translate 使用三層優先級機制,將地名轉換為精準的繁體中文。
Pack 將所有檔案打包成 50 MB 的 release.tar.gz,ready to deploy。
這套 Pipeline 的設計體現了幾個關鍵原則:資料流的單向性、階段的獨立性、ID 管理的一致性、錯誤處理的優雅性。它不僅解決了 Immich 中文地名品質的問題,更提供了一個可擴充的框架,讓任何人都能針對自己的國家客製化處理邏輯。
下一篇預告#
在本文中,我們多次提到「國家處理器(Handler)」這個概念,但並沒有深入探討它的實作細節。下一篇文章,我們將揭開處理器的面紗:
- 如何設計一個可擴充的處理器架構?
- 台灣處理器如何從 Shapefile 提取 7,000+ 個村里資料?
- 日本處理器如何處理複雜的地址系統?
- 如果你想為自己的國家開發處理器,該從哪裡開始?
敬請期待《Immich 繁體中文地理資料技術解析 (二):國家處理器架構與實作》。
參考資源#
- immich-geodata-cn README - 詳細的 GeoNames 檔案格式說明
- Immich Reverse Geocoding 原理分析 - PostGIS 查詢機制深入解析
- GeoNames Documentation - 官方檔案格式文件
- LocationIQ Documentation - Reverse Geocoding API 說明